CS 61A 2024 春季学期 Lab 12: SQL
Lab 12: SQL
截止日期:4月24日,星期三,晚上11:59
起始文件
下载 lab12.zip。在压缩包中,您可以找到本次实验的起始文件,以及 Ok 自动评分器的副本。
必做题目
SELECT 语句描述了基于输入行的输出表。编写方法:
- 使用
FROM和WHERE子句描述输入行。 - 分组这些行,并使用
GROUP BY和HAVING子句确定哪些组应显示为输出行。 - 使用
SELECT和ORDER BY子句格式化和排序输出行和列。
SELECT (步骤 3) FROM (步骤 1) WHERE (步骤 1) GROUP BY (步骤 2) HAVING (步骤 2) ORDER BY (步骤 3);
步骤 1 可能涉及连接多个表(使用逗号分隔),以形成包含来自现有表中两行或多行数据的输入行。
WHERE、GROUP BY、HAVING 和 ORDER BY 子句是可选的。
您可以查阅下拉菜单来复习 SQL 知识。如果遇到问题,可以先尝试解决,再回过头来参考这里的说明。
SQL 基础
创建表
您可以从头开始或从现有表创建 SQL 表。
以下语句展示了如何通过指定列名和值来创建一个新表,而无需引用其他表。其中,每个 SELECT 子句定义一行数据,UNION 语句用于将这些行合并在一起。AS 子句用于为每一列指定别名;在定义别名后,后续行中可以省略 AS 关键字。
CREATE TABLE [table_name] AS
SELECT [val1] AS [column1], [val2] AS [column2], ... UNION
SELECT [val3] , [val4] , ... UNION
SELECT [val5] , [val6] , ...;
例如,我们要创建一个名为 big_game 的表,用于记录每年 Big Game 的比分。该表包含三列:berkeley、stanford 和 year。
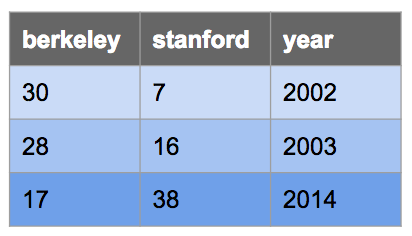
我们可以使用以下 CREATE TABLE 语句来做到这一点:
CREATE TABLE big_game AS
SELECT 30 AS berkeley, 7 AS stanford, 2002 AS year UNION
SELECT 28, 16, 2003 UNION
SELECT 17, 38, 2014;
从表中选择
通常,我们会使用 SELECT 语句从现有表中选取需要的列,从而创建一个新的表。具体用法如下:
SELECT [columns] FROM [tables] WHERE [condition] ORDER BY [columns] LIMIT [limit];
下面我们来详细解释这个语句的各个部分:
SELECT [columns]语句用于指定要在输出表中包含的列。[columns]是一个以逗号分隔的列名列表,使用*可以选择所有列。FROM [table]语句用于指定数据来源的表。要了解如何从多个表选取数据,请参考“连接”部分。WHERE [condition]语句用于过滤结果,只保留满足指定条件[condition](布尔表达式) 的行。ORDER BY [columns]语句用于按照指定的列[columns](以逗号分隔) 对结果进行排序。LIMIT [limit]语句用于限制输出结果的行数,[limit]为整数,表示返回的最大行数。
以下是一些示例:
从 big_game 表中选择所有 Berkeley 的得分,但仅包括 2002 年之后的年份的得分:
sqlite> SELECT berkeley FROM big_game WHERE year > 2002;
28
17
选择 Berkeley 获胜的年份中两所学校的得分:
sqlite> SELECT berkeley, stanford FROM big_game WHERE berkeley > stanford;
30|7
28|16
查询 Stanford 得分超过 15 分的年份:
sqlite> SELECT year FROM big_game WHERE stanford > 15;
2003
2014
SQL 运算符
SELECT、WHERE 和 ORDER BY 语句中的表达式可以包含以下一种或多种运算符:
- 比较运算符:
=、>、<、<=、>=、<>或!=(“不等于”) - 布尔运算符:
AND、OR - 算术运算符:
+、-、*、/ - 连接运算符:
||(字符串拼接)
以下是一些示例:
输出伯克利队和斯坦福队每年得分的比率:
sqlite> select berkeley * 1.0 / stanford from big_game;
0.447368421052632
1.75
4.28571428571429
输出两队得分都超过 10 分的年份,两队得分的总和:
sqlite> select berkeley + stanford from big_game where berkeley > 10 and stanford > 10;
55
44
输出一个包含单列和单行的表,其中包含值“hello world”:
sqlite> SELECT "hello" || " " || "world";
hello world
连接操作
要从多个表中选择数据,可以使用连接操作。连接操作有很多类型,但我们只需要关注内连接。 要对两个或多个表执行内连接,只需在 SELECT 语句的 FROM 子句中列出这些表:
SELECT [columns] FROM [table1], [table2], ... WHERE [condition] ORDER BY [columns] LIMIT [limit];
我们可以从多个不同的表或从同一个表多次选择。
假设我们有以下表格,其中包含自 2002 年以来加州大学伯克利分校(简称 Cal)的主教练姓名:
CREATE TABLE coaches AS
SELECT "Jeff Tedford" AS name, 2002 as start, 2012 as end UNION
SELECT "Sonny Dykes" , 2013 , 2016 UNION
SELECT "Justin Wilcox" , 2017 , null;
当我们连接两个或多个表时,默认输出结果是笛卡尔积。 例如,如果我们连接 big_game 和 coaches,我们会得到以下结果:
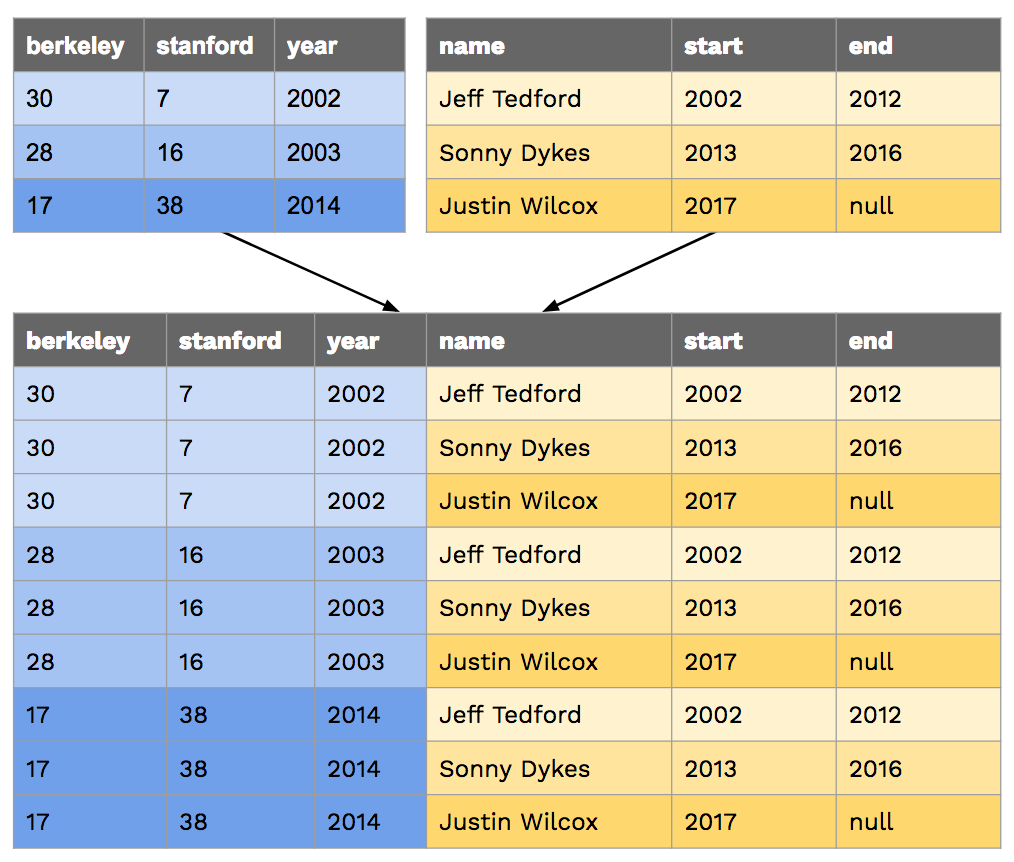
如果我们想将每场比赛与对应赛季的教练进行匹配,就需要在 WHERE 子句中比较这两个表中的相关列:
sqlite> SELECT * FROM big_game, coaches WHERE year >= start AND year <= end;
17|38|2014|Sonny Dykes|2013|2016
28|16|2003|Jeff Tedford|2002|2012
30|7|2002|Jeff Tedford|2002|2012
以下查询输出 big_game 中记录的每次 Big Game 胜利的教练和年份:
sqlite> SELECT name, year FROM big_game, coaches
...> WHERE berkeley > stanford AND year >= start AND year <= end;
Jeff Tedford|2003
Jeff Tedford|2002
在上面的查询中,所有列名都没有歧义。 例如,很明显 name 列来自 coaches 表,因为 big_game 表中没有具有该名称的列。 但是,如果列名存在于要连接的多个表中,或者如果我们用自身连接一个表,我们必须使用别名来消除列名的歧义。
例如,让我们找出 big_game 表中,每场比赛与之前任何比赛相比,每支球队的分数差值是多少。 由于此表中的每一行代表一场比赛,为了比较不同比赛之间的信息,我们需要将 big_game 表与自身进行连接:
sqlite> SELECT b.Berkeley - a.Berkeley, b.Stanford - a.Stanford, a.Year, b.Year
...> FROM big_game AS a, big_game AS b WHERE a.Year < b.Year;
-11|22|2003|2014
-13|21|2002|2014
-2|9|2002|2003
在上述查询中,我们将第一个 big_game 表格命名为别名 a,并将第二个 big_game 表格命名为别名 b。然后,我们可以使用点标记法,通过别名来引用每个表格中的列,例如 a.Berkeley、a.Stanford 和 a.Year,从而从第一个表格中选取数据。
SQL 聚合函数
此前,我们一直在处理每次处理单行的查询。当我们进行连接操作时,会生成所有行的两两组合。当我们使用 WHERE 语句时,我们会根据条件过滤掉某些行。或者,应用聚合函数(例如 MAX(column))可以将多行数据的值合并起来。
默认情况下,我们会合并整个表格的数据。例如,如果我们想计算 flights 表中的航班数量,我们可以使用:
sqlite> SELECT COUNT(*) from FLIGHTS;
13
如果我们需要将相似行的数据归为一组,并在组内执行聚合操作,该怎么办?我们使用 GROUP BY 子句。
这是另一个例子。对于每个唯一的出发地,将所有具有相同出发机场的行收集到一个组中。然后,选择 price 列并应用 MIN 聚合来恢复该组中最便宜的出发价格。最终的结果会是一个包含出发机场以及对应最便宜航班的表格。
sqlite> SELECT departure, MIN(price) FROM flights GROUP BY departure;
AUH|932
LAS|50
LAX|89
SEA|32
SFO|40
SLC|42
正如我们可以使用 WHERE 语句来过滤行,我们也可以使用 HAVING 语句来过滤分组。通常,HAVING 子句应该使用聚合函数。假设我们想查看所有至少有两个出发地的机场:
sqlite> SELECT departure FROM flights GROUP BY departure HAVING COUNT(*) >= 2;
LAX
SFO
SLC
请注意,COUNT(*) 聚合只是计算每个组中的行数。假设我们想计算不同机场的数量。那么,我们可以使用以下查询:
sqlite> SELECT COUNT(DISTINCT departure) FROM flights;
6
这枚举了 flights 表中所有可用的不同出发机场(在本例中为:SFO、LAX、AUH、SLC、SEA 和 LAS)。
用法
首先,检查名为 sqlite_shell.py 的文件是否存在于作业文件旁边。如果您没有看到它,或者遇到问题,请向下滚动到“故障排除”部分,以了解如何在继续之前下载官方预编译的 SQLite 二进制文件。
您可以使用以下命令在终端或 Git Bash 中启动交互式 SQLite 会话:
python3 sqlite_shell.py
当解释器运行时,您可以键入 .help 来查看可以运行的一些命令。
要退出 SQLite 解释器,请键入 .exit 或 .quit 或按 Ctrl-C。请注意,如果在按下回车键后看到 ...>,则很可能是忘记输入分号 ; 了。
您还可以通过执行以下操作来运行 .sql 文件中的所有语句:(这里我们使用 lab13.sql 文件作为示例。)
运行您的代码,然后立即退出 SQLite。
python3 sqlite_shell.py < lab13.sql运行您的代码,然后打开一个交互式 SQLite 会话,这类似于使用交互式
-i标志运行 Python 代码。python3 sqlite_shell.py --init lab13.sql
期末考试考场
finals 表包含列 hall(字符串)和 course(字符串),并且包含课程举行期末考试的讲堂的行。
sizes 表包含列 room(字符串)和 seats(数字),并且校园内每个唯一的房间都对应一行数据,其中包含该房间的座位数。所有讲堂都是房间。
CREATE TABLE finals AS
SELECT "RSF" AS hall, "61A" as course UNION
SELECT "Wheeler" , "61A" UNION
SELECT "Pimentel" , "61A" UNION
SELECT "Li Ka Shing", "61A" UNION
SELECT "Stanley" , "61A" UNION
SELECT "RSF" , "61B" UNION
SELECT "Wheeler" , "61B" UNION
SELECT "Morgan" , "61B" UNION
SELECT "Wheeler" , "61C" UNION
SELECT "Pimentel" , "61C" UNION
SELECT "Soda 310" , "61C" UNION
SELECT "Soda 306" , "10" UNION
SELECT "RSF" , "70";
CREATE TABLE sizes AS
SELECT "RSF" AS room, 900 as seats UNION
SELECT "Wheeler" , 700 UNION
SELECT "Pimentel" , 500 UNION
SELECT "Li Ka Shing", 300 UNION
SELECT "Stanley" , 300 UNION
SELECT "Morgan" , 100 UNION
SELECT "Soda 306" , 80 UNION
SELECT "Soda 310" , 40 UNION
SELECT "Soda 320" , 30;
Q1:大型课程
创建一个名为 big 的表,该表包含一个名为 course 的列(字符串类型),用于存储期末考试座位数至少为1000的课程名称(每行一个课程)。
你的查询应该能正确处理 finals 和 sizes 表中可能出现的任何数据,但对于上面的示例,结果应该是:
61A
61B
61C
SELECT _____ FROM _____ WHERE _____ GROUP BY _____ HAVING _____;
- 使用
FROM和WHERE组合finals和sizes表中的信息。 - 使用
GROUP BY和HAVING为每个至少有 1,000 个座位的课程创建一个分组。 - 使用
SELECT将课程名称放入输出中。
CREATE TABLE big AS
SELECT "REPLACE THIS LINE WITH YOUR SOLUTION";
使用 Ok 测试你的代码:
python3 ok -q big
Q2:剩余座位
创建一个名为 remaining 的表,其中包含两列,course(字符串)和 remaining(数字),每门课程对应一行。 每行包含课程的名称,以及该课程所有期末考场座位总数,扣除座位数最多的考场后的剩余座位数。
你的查询应该能正确处理 finals 和 sizes 表中可能出现的任何数据,但对于上面的示例,结果应该是:
10|0
61A|1800
61B|800
61C|540
70|0
SELECT course, _____ AS remaining
FROM _____ WHERE _____ GROUP BY _____;
- 使用
FROM和WHERE组合finals和sizes表中的信息。 - 使用
GROUP BY为每门课程创建一个分组。 - 使用
SELECT计算该课程所有期末考场中的座位总数,但最大的考场除外。
CREATE TABLE remaining AS
SELECT "REPLACE THIS LINE WITH YOUR SOLUTION";
使用 Ok 测试你的代码:
python3 ok -q remaining
Q3:教室共享
创建一个名为 sharing 的表,其中包含两列,course(字符串)和 shared(数字),每门课程使用至少一个也被其他课程使用的教室对应一行。 每行包含课程的名称,以及该课程与其他课程共享的教室总数。
提醒:COUNT(DISTINCT x) 用于计算每个分组中列 x 的不同值的数量。
你的查询应该能正确处理 finals 和 sizes 表中可能出现的任何数据,但对于上面的示例,结果应该是:
61A|3
61B|2
61C|2
70|1
SELECT course, COUNT(DISTINCT _____) AS shared
FROM finals AS a, finals AS b
WHERE _____ GROUP BY _____;
- 使用
FROM和WHERE为每两个课程共享同一间期末考试教室的情况创建一行。 - 使用
GROUP BY为每个课程创建一个组。 - 使用
SELECT计算该课程与其他课程共用的教室数量。
CREATE TABLE sharing AS
SELECT "REPLACE THIS LINE WITH YOUR SOLUTION";
使用 Ok 来测试你的代码:
python3 ok -q sharing
Q4: 两个教室
创建一个名为 pairs 的表,其中包含一列 rooms (字符串),其中包含描述座位总数至少为 1,000 的教室组合的句子,并包含它们的座位数。 教室名称应按字母顺序排列。 行应按教室对的总座位数降序排列。
你的查询应该适用于可能出现在 finals 和 sizes 表中的任何数据,但对于上面的示例,结果应该是:
提示: 在添加数字并将结果包含在字符串中时,请在算术运算周围加上括号:"1 + 2 = " || (1 + 2)
RSF and Wheeler together have 1600 seats
Pimentel and RSF together have 1400 seats
Li Ka Shing and RSF together have 1200 seats
Pimentel and Wheeler together have 1200 seats
RSF and Stanley together have 1200 seats
Li Ka Shing and Wheeler together have 1000 seats
Morgan and RSF together have 1000 seats
Stanley and Wheeler together have 1000 seats
SELECT _____ || " and " || _____ || " together have " || (_____) || " seats" AS rooms
FROM sizes AS a, sizes AS b WHERE _____
ORDER BY _____ DESC;
- 使用
FROM和WHERE为每对不同的教室(按字母顺序排列)创建一行,要求总座位数至少为 1,000。 - 不需要分组
CREATE TABLE pairs AS
SELECT "REPLACE THIS LINE WITH YOUR SOLUTION";
使用 Ok 来测试你的代码:
python3 ok -q pairs
在本地查看你的得分
你可以通过运行以下命令在本地检查此作业中每个问题的分数
python3 ok --score
这不会提交作业! 当你对你的分数感到满意时,将作业提交到 Gradescope 以获得学分。
提交
通过将你编辑过的任何文件上传到相应的 Gradescope 作业来提交此作业。Lab 00 包含详细说明。
此外,所有不在大型实验课的学生都必须填写此考勤表。 每周提交此表格,无论你是否参加了实验课,或者因为正当理由错过了它。 大型实验课的学生则无需填写考勤表。