Project 4: Scheme 解释器 | CS 61A Spring 2024
Eval 调用 apply, apply 又调用 eval! 这循环何时是个头啊?
介绍
提交须知:为了获得全部学分,
- 在 4 月 15 日星期一 之前提交完成的第 1 部分(计 1 分)。
- 在 4 月 18 日星期四 之前提交完成的第 2 部分和第 3 部分(包括通过
tests.scm中提供的所有测试)(计 1 分)。- 在 4 月 23 日星期二 之前提交所有阶段。 请尽量按顺序完成题目,因为后面的题目在实现上会依赖于前面的题目,运行
ok测试时也是如此。可以与合作伙伴一起完成整个项目。
在 4 月 22 日星期一 之前提交整个项目,你可以获得 1 点 EC 加分。
这个项目里,你需要开发一个 Scheme 语言子集的解释器。在进行过程中,思考在编程语言设计中出现的问题;语言的许多怪癖是解释器和编译器中实现决策的副产品。本项目使用的 Scheme 语言子集,在 Composing Programs 的函数式编程章节,以及语言规范和内置过程参考中都有详细描述。
观看关于解释器的讲座,可以帮助你了解项目的整体情况。
另外,还有一个完全可选的开放式艺术竞赛(单独发布),挑战你用几行 Scheme 代码创作递归图像。例如,上图抽象地描绘了使用美国货币兑换 0.50 美元的所有方式。所有花朵都出现在长度为 50 的分支的末端。分支中的小角度表示额外的硬币,而大角度表示新的货币面额。在比赛中,你也将有机会释放你内心的递归艺术家。
下载入门文件
你可以下载包含所有项目代码的 zip 压缩包。
你将编辑的文件:
scheme_eval_apply.py:Scheme 表达式递归求值器scheme_forms.py:特殊形式求值scheme_classes.py:描述 Scheme 表达式的类questions.scm:需要你实现的 Scheme 过程
项目中的其余文件:
scheme.py:解释器 REPLpair.py:定义Pair类和nil对象scheme_builtins.py:内置 Scheme 过程scheme_reader.py:Scheme 输入读取器scheme_tokens.py:Scheme 输入词法分析器scheme_utils.py:检查 Scheme 表达式的函数ucb.py:61A 项目的实用函数tests.scm:Scheme 测试用例集合ok:自动评测机tests:ok使用的测试目录mytests.rst:你可以在此文件中添加自己的测试
说明
该项目价值 30 分。正确性占 28 分,第一部分在第一个检查点日期前提交占 1 分,第二、三部分在第二个检查点日期前提交占 1 分。
你将提交以下文件:
scheme_eval_apply.pyscheme_forms.pyscheme_classes.pyquestions.scm
你只需修改并提交指定文件即可完成项目。 请将所需文件提交至 Gradescope 上对应的作业。
对于我们要求你完成的函数,可能会提供一些初始代码。 如果你不想使用这些代码,可以随时删除并从头开始。 你也可以根据需要添加新的函数定义。
请勿修改其他函数或编辑未列出的文件。 这样做可能会导致你的代码无法通过我们的自动评分器测试。 此外,请勿更改任何函数签名(名称、参数顺序、参数数量)。
在项目过程中,你应该经常测试代码的正确性。 经常测试是个好习惯,方便你快速定位问题。 但是,也不要过于频繁地测试,给自己留出思考的时间。
我们提供了一个名为 ok 的自动评分器,以帮助您测试代码并跟踪进度。 首次运行自动评分器时,系统会提示您通过网页浏览器登录您的 Ok 帐户,请按照指示操作。 每次运行 ok 时,它都会在我们的服务器上备份您的工作和进度。
ok 的主要目的是测试您的实现。
要以交互方式测试代码,可以运行
python3 ok -q [问题编号] -i
并插入适当的问题编号(例如 01)。 这将运行该问题的测试,直到您失败的第一个测试为止,然后让您有机会以交互方式测试您编写的函数。
您还可以通过编写以下代码来使用 OK 中的调试打印功能:
print("DEBUG:", x)
这会在终端生成调试信息,且不会干扰 OK 测试的正常运行。
解释器细节
Scheme 特性
读取-求值-打印 (Read-Eval-Print)。 解释器读取 Scheme 表达式,对其求值,并显示结果。
scm> 2
2
scm> (+ 2 3)
5
scm> ((lambda (x) (* x x)) 5)
25
您的 Scheme 解释器的起始代码可以成功地对上面的第一个表达式求值,因为它由一个数字组成。 第二个(调用内置过程)和第三个(计算 5 的平方)暂时还不能工作。
加载 (Load)。 您可以通过输入文件名来加载文件。 例如,要加载 tests.scm,请对以下调用表达式求值。
scm> (load 'tests)
符号 (Symbols)。 在 CS 61A 课程使用的 Scheme 语言中,符号(或 标识符)是由字母(a-z 和 A-Z)、数字以及 !$%&*/:<=>?@^_~-+. 中的字符组成的序列,这些字符不构成有效的整数或浮点数。
我们的 Scheme 版本不区分大小写:如果两个标识符仅在字母大小写上有所不同,则认为它们是相同的。 它们在内部以小写形式表示和打印:
scm> 'Hello
hello
海龟绘图 (Turtle Graphics)。 除了标准的 Scheme 过程之外,我们还包括对 Python turtle 包的过程调用。 这将在比赛中派上用场。
如果您好奇,可以在线阅读 turtle 模块文档。
运行解释器
要启动交互式 Scheme 解释器会话,请键入:
python3 scheme.py
要退出 Scheme 解释器,请在 Mac/Linux 上按 Ctrl-d(或在 Windows 上按 Ctrl-z Enter),或者求值 exit 过程(在完成问题 3 和 4 之后):
scm> (exit)
您可以使用 Scheme 解释器通过将文件名作为命令行参数传递给 scheme.py 来对输入文件中的表达式求值:
python3 scheme.py tests.scm
tests.scm 文件包含 Scheme 表达式及其预期值的长列表。 其中许多示例来自 计算机程序的构造和解释 的第 1 章和第 2 章,这是 Composing Programs 改编自的教科书。
快速上手视频
这些视频可能会为解决此作业中的编码问题提供一些有用的指导。
要观看这些视频,您应该登录您的 berkeley.edu 电子邮件。
第 1 部分:求值器
在第 1 部分中,您将在提供的初始代码中开发解释器的以下特性:
- 符号求值
- 调用内置过程
- 定义
在您收到的初始版本中,解释器只能对自求值表达式求值:数字、布尔值和 nil。
首先,阅读相关代码。 在 scheme_eval_apply.py 的“求值/应用 (Eval/Apply)”部分中:
scheme_eval在给定环境中对 Scheme 表达式求值。 此函数已基本完成,仅缺少处理函数调用的部分。- 在对特殊形式求值时,
scheme_eval将求值重定向到scheme_forms.py中找到的适当的do_?_form函数 scheme_apply将函数应用于指定参数。
在 scheme_classes.py 的“环境 (Environments)”和“过程 (Procedures)”部分中:
Frame类实现了环境帧。LambdaProcedure类(在“Procedures”章节中)代表用户自定义的过程。
这些是解释器的所有必要组成部分。scheme_forms.py 定义了特殊形式,scheme_builtins.py 定义了内置到标准库中的各种函数,scheme.py 定义了到解释器的用户界面。
注意: 由于所有非原子 Scheme 表达式,如调用表达式和特殊形式,本质上都是 Scheme 列表(即链表),我们使用
Pair类来表示所有非原子 Scheme 表达式,该类的行为方式与链表类似。 例如,表达式(+ 1 2)在我们的解释器中将表示为Pair('+', Pair(1, Pair(2, nil)))。 此类在pair.py中定义。 在开始项目之前,请查看此类。
使用 Ok 来测试您的理解:
python3 ok -q eval_apply -u
问题 1 (1 分)
在 scheme_classes.py 中实现 Frame 类的 define 和 lookup 方法。 每个 Frame 对象都具有以下实例属性:
bindings是一个字典,表示帧中的绑定。 每个条目将一个 Scheme 符号(以 Python 字符串表示)与一个 Scheme 值关联起来。parent是父Frame实例。 全局帧的父级为None。
在 scheme_classes.py 中:
define接受一个符号(由 Python 字符串表示)和一个值。 它将符号绑定到Frame实例中的值。lookup接受一个符号,并返回该符号在其环境中第一个绑定帧中的值。Frame实例的环境由该帧、其父帧以及所有上级帧(包括全局帧)构成。 查找符号时:- 如果符号已绑定在当前帧中,则返回其值。
- 如果符号未绑定在当前帧中,并且该帧具有父帧,则在父帧中查找该符号。
- 如果在当前帧中未找到该符号,并且没有父帧,则引发
SchemeError。
使用 Ok 来解锁和测试您的代码:
python3 ok -q 01 -u
python3 ok -q 01
完成此问题后,您可以启动 Scheme 解释器(使用 python3 scheme.py)。 您应该能够查找内置过程名称:
scm> +
#[+]
scm> odd?
#[odd?]
但是,在完成下一个问题之前,您的 Scheme 解释器仍然无法调用这些过程。
请记住,此时,您只能通过在 Max/Linux 上按 Ctrl-d(或在 Windows 上按 Ctrl-z Enter)来退出解释器。
问题 2 (2 分)
为了能够调用内置过程(例如 +),您需要在 scheme_eval_apply.py 的 scheme_apply 函数中,完善 BuiltinProcedure 对应的处理逻辑。 内置过程通过调用相应的 Python 函数来实现。
要查看项目中使用的所有 Scheme 内置过程的列表,请查看
scheme_builtins.py文件。 任何用@builtin修饰的函数都将被添加到全局定义的BUILTINS列表中。
BuiltinProcedure 具有两个实例属性:
py_func:实现内置 Scheme 过程的 Python 函数。need_env:一个布尔标志,指示此内置过程是否需要将当前环境作为最后一个参数传入。 例如,需要环境来实现内置的eval过程。
scheme_apply 接受 procedure 对象、参数值列表和当前环境。 args 是一个 Scheme 列表,表示为 Pair 对象或 nil。
您的实现应执行以下操作:
- 将 Scheme 列表转换成 Python 参数列表。 提示:
args是一个Pair,它具有.first和.rest属性。- 如果
procedure.need_env为True,则将当前环境env作为最后一个参数添加到 Python 参数列表中。- 返回对所有这些参数调用
procedure.py_func的结果。 使用*args表示法:f(1, 2, 3)等效于f(*[1, 2, 3])。 在提供的try语句块中完成此步骤,即在try:之后。
我们已经为您预先实现了以下功能:
- 如果调用函数时抛出
TypeError异常,则表示传递的参数数量有误。try语句会处理此异常,并抛出一条消息为'incorrect number of arguments'的SchemeError。
使用 Ok 来解锁并测试您的代码:
python3 ok -q 02 -u
python3 ok -q 02
👩🏽💻👨🏿💻 结对编程? 记得交换驾驶员和领航员的角色。驾驶员控制键盘;领航员观察、提问并提出想法。
问题 3 (2 分)
scheme_eval 函数(在 scheme_eval_apply.py 中)在一个环境中求值 Scheme 表达式。提供的代码已经可以在当前环境中查找符号、返回自求值表达式(例如数字)以及求值特殊形式。
实现 scheme_eval 中缺失的部分,该部分用于求值函数调用表达式。要求值函数调用表达式:
- 求值运算符(应该求值为一个
Procedure实例)。 - 求值所有操作数,并将结果(参数值)收集到一个 Scheme 列表中。
- 返回在此
Procedure和这些参数值上调用scheme_apply的结果。
您需要在前两个步骤中递归调用 scheme_eval。以下是一些您应该使用的其他函数/方法:
Pair的map方法返回一个新的 Scheme 列表,该列表是通过将一个单参数的函数应用于 Scheme 列表中的每个项目来构建的。scheme_apply函数将 Scheme 过程应用于表示为 Scheme 列表(Pair实例或nil)的参数。
重要提示:不要改变传入的
expr。这样做会改变正在求值的程序,从而产生奇怪和不正确的效果。
使用 Ok 来解锁并测试您的代码:
python3 ok -q 03 -u
python3 ok -q 03
其中一些测试调用了一个名为
print-then-return的原始(内置)过程。此过程在 Scheme 中不存在,但已添加到此项目中仅用于测试此问题。print-then-return接受两个参数。它打印出它的第一个参数并返回第二个参数。您可以在scheme_builtins.py的底部找到此函数。
您的解释器现在应该能够求值内置过程调用,从而使您能够实现计算器语言的功能,甚至更多。运行 python3 scheme.py,您现在可以添加和相乘了!
scm> (+ 1 2)
3
scm> (* 3 4 (- 5 2) 1)
36
scm> (odd? 31)
#t
问题 4 (2 分)
Scheme 中的 define 特殊形式(spec)可用于将符号分配给给定表达式的值,或创建过程并将其绑定到符号:
scm> (define a (+ 2 3)) ; 将符号 a 绑定到 (+ 2 3) 的值
a
scm> (define (foo x) x) ; 创建一个过程并将其绑定到符号 foo
foo
第一个操作数的类型决定了我们正在定义的内容:
- 如果它是一个符号,例如
a,那么表达式正在定义一个符号。 - 如果它是一个列表,例如
(foo x),那么表达式正在创建一个过程。
scheme_forms.py 中的 do_define_form 函数求值 (define ...) 表达式。此函数中有两个缺失的部分。对于此问题,仅实现第一部分,该部分求值第二个操作数以获得一个值,并将第一个操作数(一个符号)绑定到该值。然后,do_define_form 返回绑定的符号。
提示:
Frame实例的define方法在该帧内创建一个绑定。
使用 Ok 来解锁并测试您的代码:
python3 ok -q 04 -u
python3 ok -q 04
您现在应该能够将值分配给符号并求值这些符号。
scm> (define x 15)
x
scm> (define y (* 2 x))
y
scm> y
30
以下 ok 测试确定是否多次求值函数调用表达式的运算符。在抛出错误之前,运算符应该只被求值一次(因为 x 未绑定到过程)。
(define x 0)
; expect x
((define x (+ x 1)) 2)
; expect SchemeError
x
; expect 1
如果运算符被重复计算,x 最终会被绑定为 2 而不是 1,导致测试不通过。所以,如果你的代码没通过这个测试,就要确保在 scheme_eval 里,调用表达式的运算符只被计算一次。
问题 5 (1 分)
在 Scheme 中,你可以用两种方式引用表达式:使用 quote 特殊形式(spec)或者使用符号 '。解析器将 '... 转换为 (quote ...),因此你的解释器只需要评估 (quote ...) 语法。quote 特殊形式返回其操作数表达式而不对其进行计算:
scm> (quote hello)
hello
scm> '(cons 1 2) ; 等价于 (quote (cons 1 2))
(cons 1 2)
实现 scheme_forms.py 中的 do_quote_form 函数,使其仅返回 (quote ...) 表达式的未计算操作数。
使用 Ok 解锁并测试你的代码:
python3 ok -q 05 -u
python3 ok -q 05
完成此函数后,你应该能够评估引用的表达式。在你的解释器里试试这些!
scm> (quote a)
a
scm> (quote (1 2))
(1 2)
scm> (quote (1 (2 three (4 5))))
(1 (2 three (4 5)))
scm> (car (quote (a b)))
a
scm> 'hello
hello
scm> '(1 2)
(1 2)
scm> '(1 (2 three (4 5)))
(1 (2 three (4 5)))
scm> (car '(a b))
a
scm> (eval (cons 'car '('(1 2))))
1
scm> (eval (define tau 6.28))
6.28
scm> (eval 'tau)
6.28
scm> tau
6.28
提交你的第一阶段检查点
确认一下你完成了第一阶段的所有题目:
python3 ok --score
然后,在第一个检查点截止日期之前,将 scheme_eval_apply.py、scheme_forms.py、scheme_classes.py 和 questions.scm 提交到 Gradescope 上的 Scheme Checkpoint 1 作业。
运行 ok 命令时,你可能还会看到有些测试是锁定的,因为你还没完成整个项目。如果你完成了目前的所有题目,就能拿到这个检查点的全部学分。
第 2 部分:过程
在第 2 部分中,你将为解释器添加以下功能:
- Lambda 过程,使用
(lambda ...)特殊形式 - 命名过程,使用
(define (...) ...)特殊形式 - 动态作用域的 mu 过程,通过
(mu ...)这种特殊形式实现。
用户定义的过程
用户定义的 lambda 过程表示为 LambdaProcedure 类的实例。LambdaProcedure 实例具有三个实例属性:
formals是一个 Scheme 列表,包含形式参数(符号),用于指定过程的参数名称。body是表达式的 Scheme 列表;过程的主体。env是定义过程的环境。
问题 6 (1 分)
修改 scheme_eval_apply.py 里的 eval_all 函数(这个函数会被 scheme_forms.py 里的 do_begin_form 调用),来实现 begin 这种特殊形式。(spec)。
通过按顺序计算所有子表达式来计算 begin 表达式。begin 表达式的值是最后一个子表达式的值。
为了实现 begin,eval_all 函数会接收 expressions (一个包含表达式的 Scheme 列表) 和 env (代表当前环境的 Frame 对象),然后计算 expressions 里的所有表达式,并返回最后一个表达式的值。
scm> (begin (+ 2 3) (+ 5 6))
11
scm> (define x (begin (display 3) (newline) (+ 2 3)))
3
x
scm> (+ x 3)
8
scm> (begin (print 3) '(+ 2 3))
3
(+ 2 3)
如果 eval_all 接收到一个空的表达式列表 (nil),它应该返回 Python 的 None 值,这在 Scheme 中代表 undefined。
使用 Ok 解锁并测试你的代码:
python3 ok -q 06 -u
python3 ok -q 06
👩🏽💻👨🏿💻 结对编程? 现在是切换角色的好时机。切换角色可以确保你们都能从担任不同角色的学习体验中受益。
问题 7 (2 分)
在 scheme_forms.py 中实现 do_lambda_form 函数(规范),它会创建并返回一个 LambdaProcedure 实例。虽然你还不能调用用户定义的程序,但你可以通过评估一个 lambda 表达式来验证你是否正确地创建了该程序。
scm> (lambda (x y) (+ x y))
(lambda (x y) (+ x y))
在 Scheme 中,在一个过程的主体中放置多个表达式是合法的。(必须至少有一个表达式。)因此,LambdaProcedure 实例的 body 属性是一个包含主体表达式的 Scheme 列表。LambdaProcedure 实例的 formals 属性应该是一个正确嵌套的 Pair 表达式。与 begin 这种特殊形式类似,执行过程体内的代码会按顺序执行所有表达式。过程的返回值是其最后一个主体表达式的值。
使用 Ok 解锁并测试你的代码:
python3 ok -q 07 -u
python3 ok -q 07
问题 8 (2 分)
在 scheme_classes.py 中实现 Frame 类的 make_child_frame 方法,该方法将在调用用户定义的过程时用于创建新帧。此方法接收两个参数:formals,一个包含符号的 Scheme 列表;以及 vals,一个包含值的 Scheme 列表。它应该返回一个新的子帧,将形式参数绑定到对应的参数值。
为此:
- 如果参数值的数量与形式参数的数量不匹配,则引发
SchemeError。 - 创建一个新的
Frame实例,其父级为self。 - 将每个形式参数绑定到新创建的帧中对应的参数值。
formals中的第一个符号应绑定到vals中的第一个值,依此类推。 - 返回新帧。
提示:
Frame实例的define方法在该帧中创建一个绑定。
使用 Ok 解锁并测试你的代码:
python3 ok -q 08 -u
python3 ok -q 08
问题 9 (2 分)
在 scheme_eval_apply.py 中的 scheme_apply 函数中实现 LambdaProcedure 的情况。
你应该首先使用合适的父帧的 make_child_frame 方法创建一个新的 Frame 实例,并将形式参数绑定到参数值。然后,使用 eval_all 在这个新帧中评估过程主体的每个表达式。
重要提示: 你创建的新帧应该是定义 lambda 表达式的帧的子帧。请注意,传递给 scheme_apply 的 env 参数是调用该过程时所在的帧。请参考用户定义的程序部分,回顾 LambdaProcedure 的属性。
使用 Ok 解锁并测试你的代码:
python3 ok -q 09 -u
python3 ok -q 09
问题 10 (1 分)
目前,你的 Scheme 解释器能够以下列方式将符号绑定到用户定义的过程:
scm> (define f (lambda (x) (* x 2)))
f
但是,我们希望能够使用定义命名过程的简写形式:
scm> (define (f x) (* x 2))
f
修改 scheme_forms.py 中的 do_define_form 函数,以便它正确处理 define (...) ...) 表达式(规范)。
确保它能处理包含多个表达式的函数体。例如,
scm> (define (g y) (print y) (+ y 1))
g
scm> (g 3)
3
4
解决这个问题至少有两种方法。一种是构造一个表达式 (define _ (lambda ...)) 并在其上调用 do_define_form(省略 define)。第二种是直接实现它:
- 利用给定的变量
signature和expressions,找到已定义函数的名称(符号)、形式参数和函数体。 - 使用形式参数和函数体创建一个
LambdaProcedure实例。(可以调用do_lambda_form来完成此操作。) - 将该符号绑定到这个新的
LambdaProcedure实例上。 - 返回被绑定的那个符号。
使用 Ok 来解锁并测试你的代码:
python3 ok -q 10 -u
python3 ok -q 10
问题 11 (1 pt)
目前为止,我们见过的 Scheme 过程都使用词法作用域:新调用帧的父帧是该过程定义时所在的环境。另一种作用域类型,动态作用域,在 Scheme 中不常见,但在 Lisp 的其他变体中有所应用:新调用帧的父帧是该调用表达式被求值时所在的环境。使用动态作用域,从代码的不同部分使用相同的参数调用相同的过程可能会产生不同的行为(由于不同的父帧)。
mu 特殊形式(spec;为此项目发明)求值为一个动态作用域的过程。
scm> (define f (mu () (* a b)))
f
scm> (define g (lambda () (define a 4) (define b 5) (f)))
g
scm> (g)
20
在上面,过程 f 没有 a 或 b 作为参数;但是,由于 f 在过程 g 内部被调用,因此它可以访问在 g 的帧中定义的 a 和 b。
你的任务:
- 在
scheme_forms.py中实现do_mu_form,用于求值mu特殊形式。mu表达式求值为一个MuProcedure。MuProcedure类(在scheme_classes.py中定义)已为你提供。 - 除了实现
do_mu_form之外,还需要完成scheme_apply函数(位于scheme_eval_apply.py)中关于MuProcedure的情况,确保在调用mu过程时,其函数体在正确的环境中求值。当调用MuProcedure时,新调用帧的父帧是该调用表达式被求值时所在的环境。因此,MuProcedure无需将环境存储为实例属性。
使用 Ok 来解锁并测试你的代码:
python3 ok -q 11 -u
python3 ok -q 11
在项目的这一点上,你的 Scheme 解释器应该支持以下功能:
- 使用
lambda和mu表达式创建过程, - 使用
define表达式定义命名过程,以及 - 调用用户定义的过程。
第 3 部分:特殊形式
本节将在 scheme_forms.py 中完成。
逻辑特殊形式包括 if、and、or 和 cond。这些表达式很特殊,因为并非所有子表达式都可以被求值。
在 Scheme 中,只有 #f 是假值。所有其他值(包括 0 和 nil)都是真值。你可以使用 scheme_utils.py 中定义的 Python 函数 is_scheme_true 和 is_scheme_false 来判断一个值是真值还是假值。
Scheme 传统上使用
#f来表示假布尔值。在我们的解释器中,这等同于false或False。类似地,true、True和#t都等效。但是,在解锁测试时,请使用#t和#f。
为了帮助你入门,我们已经在 do_if_form 函数中提供了 if 特殊形式的实现。在开始以下问题之前,请确保你理解该实现。
问题 12 (2 pt)
实现 do_and_form 和 do_or_form,以便正确评估 and 和 or 表达式(spec)。
逻辑运算符 and 和 or 具有短路求值特性。 对于 and 运算符,解释器应从左至右计算每个子表达式。如果任一子表达式为假值,则直接返回该假值。 否则,返回最后一个子表达式的计算结果。 如果 and 表达式不包含任何子表达式,则其结果为 #t。
scm> (and)
#t
scm> (and 4 5 6) ; 所有操作数均为真值
6
scm> (and 4 5 (+ 3 3))
6
scm> (and #t #f 42 (/ 1 0)) ; and 运算符的短路求值特性
#f
在解释器内部,Scheme 的
#t和#f分别用 Python 的True和False表示。
对于 or 运算符,解释器应从左至右计算每个子表达式。如果任一子表达式为真值,则直接返回该真值。 否则,返回最后一个子表达式的计算结果。 如果 or 表达式不包含任何子表达式,则其结果为 #f。
scm> (or)
#f
scm> (or 5 2 1) ; 5 是一个真值
5
scm> (or #f (- 1 1) 1) ; 在 Scheme 中,0 被视为真值
0
scm> (or 4 #t (/ 1 0)) ; or 运算符的短路求值特性
4
重要提示: 请使用 scheme_utils.py 文件中提供的 is_scheme_true 和 is_scheme_false Python 函数来判断 Scheme 中的布尔值。
使用 Ok 解锁并测试你的代码:
python3 ok -q 12 -u
python3 ok -q 12
问题 13 (2 分)
请补全 scheme_forms.py 文件中的 do_cond_form 函数,以正确实现 cond 表达式(规范)。该函数应返回与第一个计算结果为真的谓词相对应的结果子表达式的值;如果存在 else 分支,则返回其对应结果子表达式的值。
一些特殊情况:
- 当真谓词没有对应的结果子表达式时,返回谓词值。
- 如果
cond表达式的结果子表达式包含多个表达式,则应依次计算所有表达式,并返回最后一个表达式的计算结果(提示:使用eval_all函数)。
你的实现应该与以下示例和 tests.scm 中的其他测试相匹配。
scm> (cond ((= 4 3) 'nope)
((= 4 4) 'hi)
(else 'wait))
hi
scm> (cond ((= 4 3) 'wat)
((= 4 4))
(else 'hm))
#t
scm> (cond ((= 4 4) 'here (+ 40 2))
(else 'wat 0))
42
如果 cond 表达式中没有任何谓词为真,且不存在 else 分支,则该表达式的结果为 undefined。此时,do_cond_form 函数应返回 None。如果仅存在 else 分支,则返回其结果子表达式的计算结果;如果 else 分支没有结果子表达式,则返回 #t。
scm> (cond (False 1) (False 2))
scm> (cond (else))
#t
使用 Ok 解锁并测试你的代码:
python3 ok -q 13 -u
python3 ok -q 13
问题 14 (2 分)
let 表达式(规范)用于在局部作用域内将符号绑定到值,从而赋予它们初始值。 例如:
scm> (define x 5)
x
scm> (define y 'bye)
y
scm> (let ((x 42)
(y (* x 10))) ; 此处的 `x` 引用的是全局作用域中的 `x`,而非 42
(list x y))
(42 50)
scm> (list x y)
(5 bye)
在 scheme_forms.py 中实现 make_let_frame,它返回 env 的一个子帧,该子帧将 bindings 中每个元素的符号绑定到其对应表达式的值。 bindings Scheme 列表包含成对的元素,每个元素包含一个符号和一个对应的表达式。
以下函数和方法可能会对您有所帮助:
validate_form: 此函数用于验证每个绑定的结构是否符合规范。它接受一个 Scheme 列表expr,该列表包含多个表达式,并接受最小长度min和最大长度max。如果expr的长度不在min和max(包含min和max) 之间,则会抛出一个错误。如果没有指定max,则默认长度为无穷大。validate_formals: 此函数验证其参数是否为一个由不重复的 Scheme 符号组成的列表。
提示: 在迭代构建新的链表时,从右到左构建可能会更容易。
如果对测试用例有任何疑问,请参考 spec!
使用 Ok 来解锁和测试您的代码:
python3 ok -q 14 -u
python3 ok -q 14
附加 Scheme 测试(1 分)
您在此项目第三部分的最终任务是确保您的 Scheme 解释器能够通过我们提供的附加测试套件。
要运行这些测试 (共 1 分),请运行以下命令:
python3 ok -q tests.scm
如果因为调试时添加的 print 语句导致测试失败,请删除这些语句以确保测试通过。如果您已通过所有必需的用例,则在运行 python ok --score 时,您应该会看到 tests.scm 获得 1/1 分。
提交您的第 2 和第 3 阶段检查点
请检查您是否已经完成了第一阶段的所有问题:
python3 ok --score
然后,在第二个检查点截止日期之前,将 scheme_eval_apply.py、scheme_forms.py、scheme_classes.py 和 questions.scm 提交到 Gradescope 上的 Scheme Checkpoint 2 作业。
当您运行 ok 命令时,您仍然会看到某些测试被锁定,因为您尚未完成整个项目。如果您完成到目前为止的所有问题,您将获得检查点的全部学分。
恭喜!您的 Scheme 解释器实现现已完成!
第 4 部分:编写一些 Scheme
您的 Scheme 解释器不仅本身是一个树递归程序,而且足够灵活,可以执行其他递归程序。请在 questions.scm 文件中实现以下过程。
有关所有内置 Scheme 过程的行为描述,请参阅内置过程参考。
在使用解释器的过程中,您可能会发现解释器实现中存在其他错误。因此,在官方提供的解释器或 Web 编辑器 中测试您的代码会很有帮助。 确认 Scheme 代码能够正常工作后,再在您自己的解释器中尝试运行。您还可以使用 Web 编辑器来可视化您编写的 Scheme 代码并帮助您进行调试。
Scheme 编辑器
在编写代码时,您可以使用本地 Scheme 编辑器进行调试。要运行此编辑器,请运行 python3 editor。这应该在您的浏览器中打开一个窗口;如果它没有打开,请导航到 localhost:31415,您应该会看到它。
确保在单独的选项卡或窗口中运行 python3 ok,以便编辑器保持运行。
👩🏽💻👨🏿💻 结对编程? 记得轮流担任驾驶员和导航员的角色。
问题 15(2 分)
实现 enumerate 过程,该过程接受一个值列表,并返回一个由两元素列表组成的列表,其中第一个元素是值的索引,第二个元素是值本身。
scm> (enumerate '(3 4 5 6))
((0 3) (1 4) (2 5) (3 6))
scm> (enumerate '())
()
使用 Ok 测试您的代码:
python3 ok -q 15
问题 16(2 分)
实现 merge 过程,该过程接受一个比较函数 ordered? 和两个已根据该比较函数排序的列表,并将它们合并为一个新的排序列表。比较函数通过比较两个值来定义排序规则,如果两个值符合排序规则,则返回真值。
scm> (merge < '(1 4 6) '(2 5 8))
(1 2 4 5 6 8)
scm> (merge > '(6 4 1) '(8 5 2))
(8 6 5 4 2 1)
scm> (merge < '(1) '(2 3 5))
(1 2 3 5)
如果出现平局的情况,你可以选择任何方式来打破平局。
使用 Ok 来测试你的代码:
python3 ok -q 16
可选问题
可选问题 1 (0 分)
在这个问题中,你将实现尾调用优化,这是 Scheme 语言的一个重要特性。观看此播放列表以了解尾调用。
我们将通过使用一种称为“蹦床 (trampolining) 技术”——一种通过跳板技术实现尾调用优化的方法——来在 Scheme 中实现尾调用优化,以尾调用优化我们的 scheme_eval 函数(在 Python 中)。
scheme_eval 是我们解释器的核心,它是一个树状递归函数。因此,当我们首次调用 scheme_eval 时,会紧接着产生大量的递归调用。例如,即使是下面这个简单的 foo 过程:在 Scheme 解释器中执行 (foo 4) 也会导致 scheme_eval 被调用 52 次。
(define (foo n)
(if (= n 0)
0
(foo (- n 1))))
如果我们只关注提供的 expr 是对 foo 的调用的 scheme_eval 调用,我们会看到一个有趣的模式:
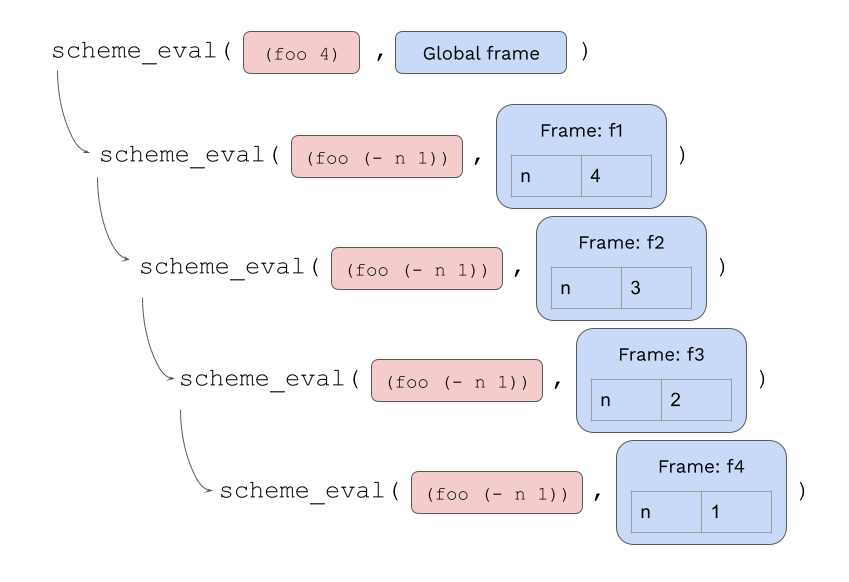
scheme_eval 进行的递归调用的结构与 foo 进行的递归调用的结构非常相似:
- 计算
(foo 4)的scheme_eval调用最终会对计算(foo 3)的scheme_eval进行递归调用。计算(foo 3)的scheme_eval调用最终会对计算(foo 2)的scheme_eval进行递归调用,依此类推。 - 在 Scheme 中,
(foo 4)调用期间发生的最后一件事是对确定(foo 3)进行递归调用。类似地,在 Python 中,计算(foo 4)的scheme_eval调用期间发生的最后一件事是对scheme_eval进行递归调用以确定(foo 3)。换句话说,这些scheme_eval调用就是尾调用! - 在 Python 中,会打开并保留大量的
scheme_eval帧。这些scheme_eval帧中的每一个都保存对foo帧的引用(由Frame类的实例表示)。我们当前的解释器保留这些不必要的foo帧的原因是它也在保留这些scheme_eval帧。
因为某些 scheme_eval 调用是尾调用,所以我们不需要保留所有在 Python 中创建的那些帧。这意味着我们可以对 scheme_eval 进行尾调用优化。并且因为 Scheme 帧存储在 scheme_eval 调用帧上,所以在 Python 中尾调用优化 scheme_eval 将会对整个 Scheme 中的解释器进行尾调用优化。
事实证明,尾调用优化 scheme_eval 除了能优化 Scheme 之外,还有其他益处。例如,像 (or #f (or #f (or #f f ))) 这样的表达式,优化后运行效率会显著提高。
这是一个简单的递归过程 foo,它没有做太多事情。
(define (foo n)
(if (= n 0)
0
(foo (- n 1))))
在你的非尾调用优化版本的 Scheme 中,当我们调用 foo(4) 时会发生以下情况:
 为了计算
为了计算 (foo 4),我们需要调用 (foo 3)。为了计算 (foo 3),我们需要调用 (foo 2)。为了计算 (foo 2),我们需要调用 (foo 1)。为了计算 (foo 1),我们需要调用 (foo 0),它会返回 0。当所有这些递归调用发生时,每次调用都会等待下一个递归调用的结果,其堆栈帧也会在这段时间内保持打开。对于小的输入,这是可以管理的,但是对于 (foo 1000000),在某个时刻将同时打开超过 100 万个堆栈帧!这可能会导致您的计算机崩溃。
在大多数情况下,这种在后续调用期间保持这些堆栈帧处于活动状态的做法非常重要。例如,在下面的代码中,f 调用 g;在调用 g 正在进行时,f 的堆栈帧需要保持活动状态,以便我们最终可以返回到 f 并完成代码。
(define (f x)
(define y (g x))
(* x y))
(define (g x)
(* 6 x))
(f 7)
但是,某些函数(例如 foo)仅在最后进行函数调用。因为 (foo 4) 做的最后一件事就是调用 (foo 3),所以一旦 (foo 3) 返回,(foo 4) 的调用就结束了,没有后续操作。因此,我们实际上没有必要继续保留 (foo 4) 的堆栈帧。我们的解释器当前正在保存这些堆栈帧,即使它们是冗余的。如果我们能在完成这些堆栈帧后摆脱它们,我们将解决 foo 的大型输入崩溃的问题,并显着提高程序的效率。
在这种情况下,调用是函数在返回之前评估的最后一件事,该调用被称为处于尾调用位置中。Scheme 的完整实现都实现了尾调用优化,该优化涉及丢弃不必要的堆栈帧,以便尾调用可以更有效地运行。
蹦床法是一种在通常不支持尾调用优化的语言(例如 Python)中实现尾调用优化的方法,方法是将尾调用位置中的函数调用存储为未评估的调用(Thunk),然后仅在需要时才评估和展开它们(蹦床法)。
此方法的基本单元是 Thunk,它表示未评估的操作。实现此效果的最简单方法是将操作包装在零参数函数中,保存以供以后评估:
>>> my_thunk1 = lambda: sqrt(16384) + 22
>>> my_thunk2 = lambda: some_costly_operation(1000)
可以通过调用该函数来“展开”这些函数,该函数最终会评估其内部。
>>> my_thunk1()
150.0
>>> my_thunk2()
# result of evaluating some_costly_operation(1000)
这些 thunk 也可以嵌套,需要多次调用:
>>> my_nested_thunk = lambda: lambda: lambda: 4 * (2 + 3)
>>> thunk2 = my_nested_thunk()
>>> thunk3 = thunk2()
>>> result = thunk3()
>>> result
20
嵌套 thunk 的这种“展开”是我们称之为蹦床法的过程,它可以自动完成,调用 thunk 直到它最终返回一个值。
def trampoline(value):
while callable(value): # While value is still a thunk
value = value()
return value
这样做有什么好处呢?考虑我们的尾调用优化阶乘:
def tail_factorial(n, so_far=1):
if n == 0:
return so_far
return tail_factorial(n - 1, so_far * n)
由于 Python 不优化尾调用,因此每次递归调用都会创建一个新的堆栈帧,并且只有在递归结束时才会被关闭,这使得它和最初的实现一样低效!将此可视化为调用堆栈:
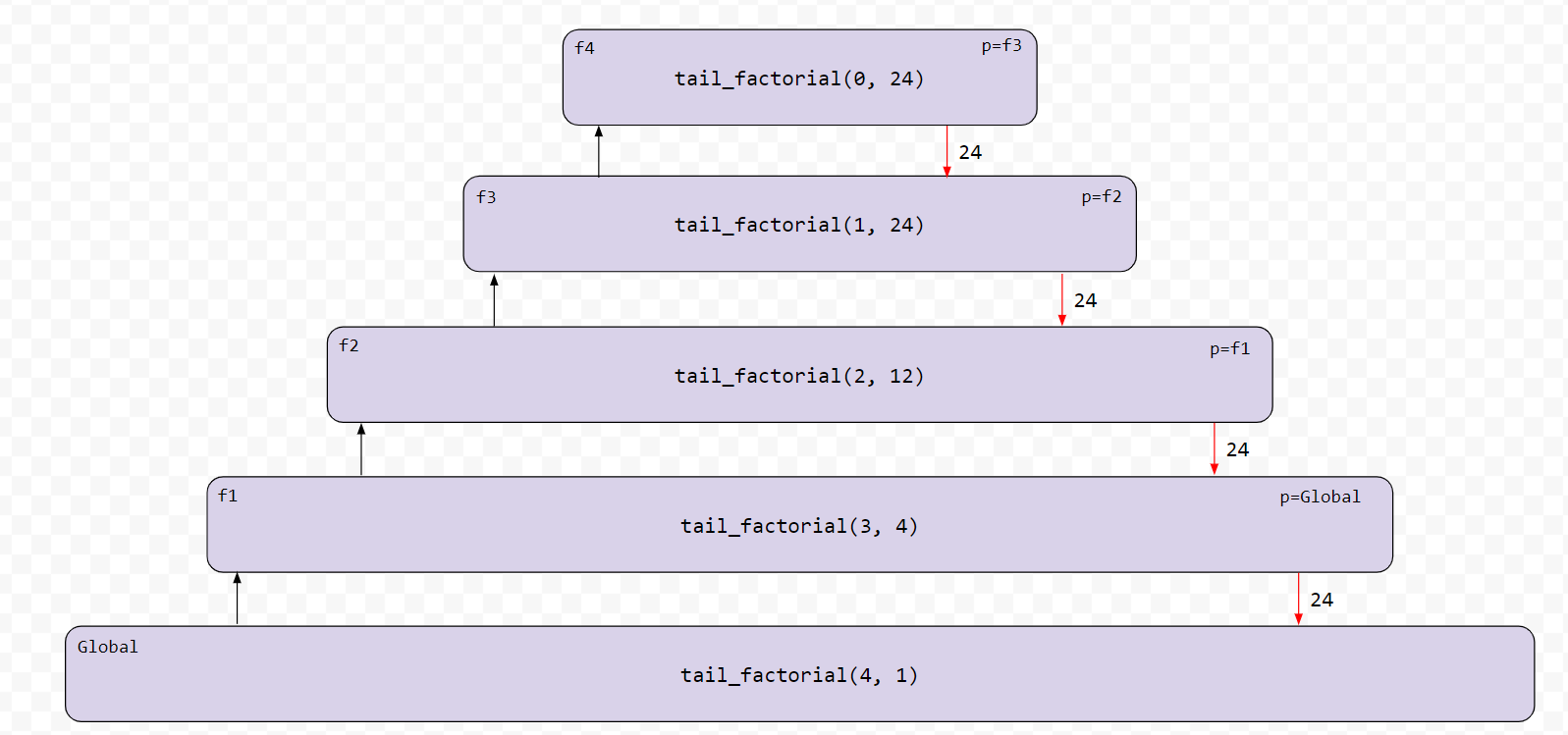
您可以看到,到我们到达基本情形时,每个 tail_factorial 堆栈帧仍然是打开的!为了解决这个问题,我们可以采用 Thunk 技术!Thunk 技术通过让每次调用只计算阶乘的一个步骤,然后返回一个未计算的 Thunk,而不是进行嵌套调用,从而保持只有一个 thunk_factorial 堆栈帧处于打开状态。实现如下所示:
def thunk_factorial(n, so_far=1):
def thunk():
if n == 0:
return so_far
return thunk_factorial(n - 1, so_far * n)
return thunk
def factorial(n):
value = thunk_factorial(n)
while callable(value): # While value is still a thunk
value = value()
return value
为了阐释其优势,请参考函数调用的新图表,并与最初的尾递归版本进行对比:
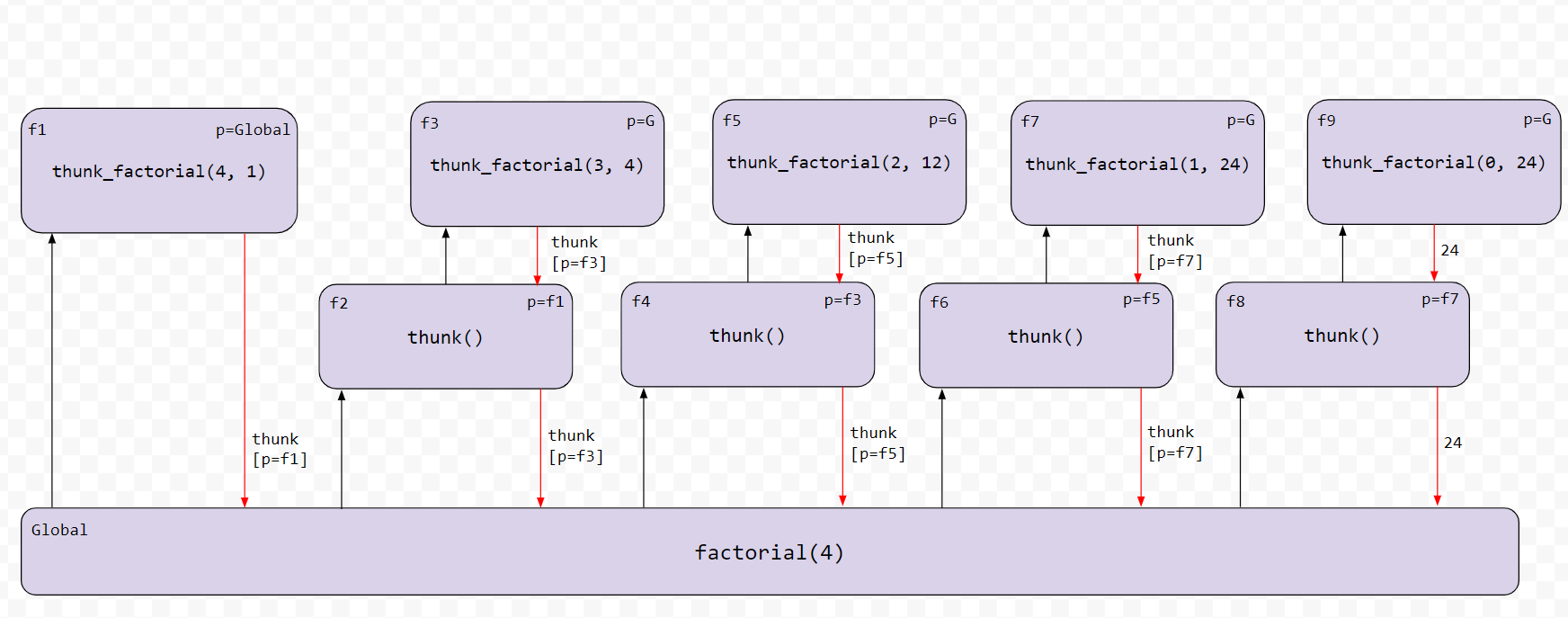
尽管thunk处理后的版本初看之下可能更为复杂,但请注意,任何时刻都至多只有一个thunk_factorial和thunk调用处于活动状态。无论n的值变得多大,这个结论都成立!在每个步骤,调用当前的thunk会精确计算阶乘的一个步骤,然后返回一个新的thunk以供下一步使用,从而使整个过程得以在下一次循环中继续进行。
您还可以通过观察这个逐步图表来更深入地理解,该图表详细展示了factorial(3)第一部分的求值过程。

由此可见,从thunk_factorial返回一个未求值的thunk,而非递归调用自身,使得已经完成求值的开放帧得以关闭,从而在任何给定时刻仅保持必要的帧处于开放状态。
对于我们的 Scheme 解释器,Unevaluated 实例是 scheme_eval 的 thunk,我们希望对其进行优化。我们通过在存储的参数上调用 scheme_eval 来重复评估此 thunk,直到我们得到一个值(我们返回该值)。
请完成scheme_eval_apply.py文件中的optimize_tail_calls函数。它返回 scheme_eval 的替代方案,该替代方案在 Python 中进行了尾调用优化。也就是说,它允许无限数量的活动尾调用在恒定的空间内调用scheme_eval。它包含第三个参数tail,用于指示对scheme_eval的调用是否为尾调用。
Unevaluated 类表示需要在环境中评估的表达式。当optimized_eval在尾部上下文中接收到非原子表达式时,它会返回一个Unevaluated实例。反之,它应该在当前的expr和env上重复调用unoptimized_scheme_eval,直到结果为一个值,而非Unevaluated实例。
此外,整个解释器中对 scheme_eval 的所有尾调用都应该通过使用 True 作为第三个参数(现在称为 tail)调用 scheme_eval 来评估。您的目标是确定哪些对scheme_eval的调用属于尾调用,并根据实际需求修改tail的值。成功的实现将需要更改多个其他函数,包括我们为您提供的一些函数。
如果对
scheme_eval的调用是函数返回前执行的最后一步操作,那么该调用即为尾调用。在讲座中,您学习了有关如何在 Scheme 中查找尾部上下文的规则。由于我们试图对我们的 Python 函数
scheme_eval进行尾调用优化,因此这些规则并不完全适用于 Python。
完成后,取消注释 scheme_eval_apply.py 中的以下行以使用您的实现:
scheme_eval = optimize_tail_calls(scheme_eval)
使用 Ok 测试您的代码:
python3 ok -q optional1
可选问题 2 (0 pt)
在Scheme语言中,源代码即数据。每个非原子表达式均可表示为Scheme列表,因此我们可以像编写操作列表的程序一样,编写操作其他程序的程序。
重写程序可能很有用:我们可以编写一个只处理语言的一小部分核心的解释器,然后编写一个过程,在程序传递给解释器之前将其他特殊形式转换为核心语言。
例如,let特殊形式等价于一个以lambda表达式开头的函数调用。两者都创建一个新帧,扩展当前环境并在该新环境中评估一个主体。
(let ((a 1) (b 2)) (+ a b))
;; 等价于:
((lambda (a b) (+ a b)) 1 2)
这些表达式可以通过以下图表进行可视化:
使用此规则在 questions.scm 中实现一个名为 let-to-lambda 的过程,该过程将所有 let 特殊形式重写为 lambda 表达式。如果我们引用一个 let 表达式并将其传递给此过程,则应返回一个等效的 lambda 表达式:
scm> (let-to-lambda '(let ((a 1) (b 2)) (+ a b)))
((lambda (a b) (+ a b)) 1 2)
scm> (let-to-lambda '(let ((a 1)) (let ((b a)) b)))
((lambda (a) ((lambda (b) b) a)) 1)
scm> (let-to-lambda 1)
1
scm> (let-to-lambda 'a)
a
为了正确处理所有Scheme程序,let-to-lambda必须理解Scheme的语法。 因为Scheme表达式是递归定义的,所以let-to-lambda函数也需要使用递归的方式来实现。 实际上,let-to-lambda的结构和scheme_eval有些相似,都是用Scheme语言编写的! 需要提醒的是,原子包括数字,布尔值,nil和符号这些基本类型。 对于此问题,您无需考虑包含准引用的代码。
(define (let-to-lambda expr)
(cond ((atom? expr) <处理原子类型>)
((quoted? expr) <处理引用表达式>)
((lambda? expr) <处理lambda表达式>)
((define? expr) <处理define表达式>)
((let? expr) <处理let表达式>)
(else <处理其他表达式>)))
提示一:考虑如何使用 map 将列表中每个元素的 let 形式转换为等效的 lambda 形式? 考虑使用 zip:
scm> (zip '((1 2) (3 4) (5 6)))
((1 3 5) (2 4 6))
scm> (zip '((1 2)))
((1) (2))
scm> (zip '())
(() ())
提示二:在此问题中,构建一个可以被求值为特定类型的Scheme列表(例如lambda表达式)会很有帮助。 下面的例子展示了如何构建一个Scheme列表,使其求值结果为表达式(define (f x) (+ x 1)):
(let ((name-and-params '(f x))
(body '(+ x 1)))
(cons 'define
(cons name-and-params (cons body nil))))
使用 Ok 测试您的代码:
python3 ok -q optional2
如果我们需要在一个不支持
let语法的解释器中运行let-to-lambda,该怎么办呢? 我们可以将let-to-lambda函数传递给自己,从而将它重写成一个不包含let语法的等价程序。;; let-to-lambda 过程
(define (let-to-lambda expr)
...)
;; 表示 let-to-lambda 过程的列表
(define let-to-lambda-code
'(define (let-to-lambda expr)
...))
;; 一个不使用 'let' 的 let-to-lambda 过程!
(define let-to-lambda-without-let
(let-to-lambda let-to-lambda-code))
结论
恭喜! 您已经完成了一个语言解释器的实现! 如果您喜欢这个项目并想进一步扩展它,您可能有兴趣查看更高级的功能,例如 let* 和 letrec、unquote splicing、错误跟踪 和 延续。
项目提交
运行ok命令,确保所有测试都已经解锁并且通过。
python3 ok
您还可以检查您在项目每个部分中的得分:
python3 ok --score
一旦您满意,请在第二个检查点截止日期之前,将 scheme_eval_apply.py、scheme_forms.py、scheme_classes.py 和 questions.scm 提交到 Gradescope 上的 Scheme 作业。
您可以在Gradescope提交页面右侧,点击您的姓名下方的“+ 添加组成员”来添加合作伙伴。 只需要一个合作伙伴提交到 Gradescope。