使用数据库和 SQL
什么是数据库?
数据库 (database) 是一个用于存储数据的有组织的文件。大多数数据库的组织方式类似于字典,因为它们都将键映射到值。最大的区别在于数据库位于磁盘(或其他永久存储)上,因此在程序结束后仍然存在。由于数据库存储在永久存储上,它可以存储比字典多得多的数据,而字典的大小受限于计算机内存的大小。
与字典类似,数据库软件被设计用来即使处理大量数据也能非常快速地插入和访问数据。数据库软件通过在向数据库添加数据时建立索引 (indexes) 来保持其性能,从而允许计算机快速跳转到特定条目。
有许多不同的数据库系统用于各种目的,包括:Oracle、MySQL、Microsoft SQL Server、PostgreSQL 和 SQLite。本书我们重点关注 SQLite,因为它是一个非常常见的数据库,并且已经内置在 Python 中。SQLite 被设计为嵌入 (embedded) 到其他应用程序中,以在应用程序内部提供数据库支持。例如,Firefox 浏览器内部也使用 SQLite 数据库,许多其他产品也是如此。
SQLite 非常适合我们在信息学中看到的一些数据处理问题。
数据库概念
当你第一次看到数据库时,它看起来像一个包含多个工作表的电子表格。数据库中的主要数据结构是:表 (tables)、行 (rows) 和列 (columns)。
 关系型数据库
关系型数据库
在关系数据库的技术描述中,表、行和列的概念更正式地称为关系 (relation)、元组 (tuple) 和属性 (attribute)。在本章中,我们将使用不太正式的术语。
SQLite 数据库浏览器
虽然本章将重点介绍使用 Python 处理 SQLite 数据库文件中的数据,但许多操作可以使用名为 Database Browser for SQLite 的软件更方便地完成,该软件可从以下地址免费获取:
使用该浏览器,你可以轻松地创建表、插入数据、编辑数据或对数据库中的数据运行简单的 SQL 查询。
从某种意义上说,数据库浏览器类似于处理文本文件时的文本编辑器。当你想对文本文件执行一个或很少几个操作时,你只需在文本编辑器中打开它并进行所需的更改。当你需要对文本文件进行许多更改时,通常你会编写一个简单的 Python 程序。在处理数据库时,你会发现同样的模式。你将在数据库管理器中执行简单的操作,而更复杂的操作将最方便地在 Python 中完成。
创建数据库表
数据库比 Python 列表或字典需要更明确的结构 1。
当我们创建数据库表时,我们必须事先告诉数据库表中每个列的名称以及我们计划在每个列中存储的数据类型。当数据库软件知道每列中的数据类型时,它可以根据数据类型选择最有效的方式来存储和查找数据。
你可以在以下网址查看 SQLite 支持的各种数据类型:
http://www.sqlite.org/datatypes.html
预先为你的数据定义结构一开始可能看起来不方便,但回报是即使数据库包含大量数据,也能快速访问你的数据。
创建数据库文件和数据库中名为 Track 且包含两列的表的代码如下:
import sqlite3
conn = sqlite3.connect('music.sqlite')
cur = conn.cursor()
cur.execute('DROP TABLE IF EXISTS Track')
cur.execute('CREATE TABLE Track (title TEXT, plays INTEGER)')
conn.close()
# 代码: https://www.py4e.com/code3/db1.py
connect 操作与存储在当前目录 music.sqlite 文件中的数据库建立“连接”。如果文件不存在,则会创建该文件。之所以称为“连接”,是因为有时数据库存储在与我们运行应用程序的服务器不同的单独“数据库服务器”上。在我们的简单示例中,数据库只是与我们运行的 Python 代码位于同一目录中的本地文件。
游标 (cursor) 类似于文件句柄,我们可以使用它对存储在数据库中的数据执行操作。调用 cursor() 在概念上与处理文本文件时调用 open() 非常相似。
 数据库游标
数据库游标
一旦我们有了游标,就可以开始使用 execute() 方法在数据库内容上执行命令。
数据库命令使用一种特殊语言表达,该语言已在许多不同的数据库供应商之间标准化,使我们能够以可移植的方式与来自多个供应商的数据库系统进行通信。该数据库语言称为结构化查询语言 (Structured Query Language),简称 SQL。
http://en.wikipedia.org/wiki/SQL
在我们的示例中,我们在数据库中执行了两个 SQL 命令。按照惯例,我们将以大写形式显示 SQL 关键字,而我们添加的命令部分(例如表名和列名)将以小写形式显示。
第一个 SQL 命令如果 Track 表存在,则将其从数据库中移除。这种模式只是为了允许我们重复运行相同的程序来创建 Track 表而不会导致错误。请注意,DROP TABLE 命令会从数据库中删除该表及其所有内容(即,没有“撤消”操作)。
cur.execute('DROP TABLE IF EXISTS Track ')
第二个命令创建一个名为 Track 的表,其中包含一个名为 title 的文本列和一个名为 plays 的整数列。
cur.execute('CREATE TABLE Track (title TEXT, plays INTEGER)')
现在我们已经创建了一个名为 Track 的表,我们可以使用 SQL INSERT 操作将一些数据放入该表中。同样,我们首先建立与数据库的连接并获取 cursor。然后我们可以使用游标执行 SQL 命令。
SQL INSERT 命令指示我们正在使用的表,然后通过列出我们想要包含的字段 (title, plays),后跟我们想要放置在新行中的 VALUES 来定义一个新行。我们将值指定为问号 (?, ?),以指示实际值作为元组 ('My Way', 15) 作为 execute() 调用的第二个参数传入。
import sqlite3
conn = sqlite3.connect('music.sqlite')
cur = conn.cursor()
cur.execute('INSERT INTO Track (title, plays) VALUES (?, ?)',
('Thunderstruck', 20))
cur.execute('INSERT INTO Track (title, plays) VALUES (?, ?)',
('My Way', 15))
conn.commit()
print('Track:')
cur.execute('SELECT title, plays FROM Track')
for row in cur:
print(row)
cur.execute('DELETE FROM Track WHERE plays < 100')
conn.commit()
cur.close()
# 代码: https://www.py4e.com/code3/db2.py
首先,我们向表中 INSERT 两行,并使用 commit() 强制将数据写入数据库文件。
 表中的行
表中的行
然后我们使用 SELECT 命令从表中检索我们刚刚插入的行。在 SELECT 命令上,我们指示我们想要哪些列 (title, plays) 并指示我们想从哪个表中检索数据。执行 SELECT 语句后,游标是我们在 for 语句中可以循环遍历的东西。为了提高效率,当我们执行 SELECT 语句时,游标不会从数据库中读取所有数据。相反,数据是在我们循环遍历 for 语句中的行时按需读取的。
程序的输出如下:
Track:
('Thunderstruck', 20)
('My Way', 15)
我们的 for 循环找到两行,每一行都是一个 Python 元组,第一个值是 title,第二个值是 plays 的数量。
在程序的最后,我们执行一个 SQL 命令来 DELETE 我们刚刚创建的行,这样我们就可以重复运行程序。DELETE 命令展示了 WHERE 子句的用法,它允许我们表达一个选择标准,以便我们可以要求数据库仅将命令应用于匹配该标准的行。在这个例子中,该标准恰好适用于所有行,所以我们清空表,以便可以重复运行程序。执行 DELETE 后,我们还调用 commit() 来强制从数据库中移除数据。
结构化查询语言摘要
到目前为止,我们一直在 Python 示例中使用结构化查询语言,并涵盖了 SQL 命令的许多基础知识。在本节中,我们将特别关注 SQL 语言并概述 SQL 语法。
由于数据库供应商众多,结构化查询语言(SQL)被标准化,以便我们可以以可移植的方式与来自多个供应商的数据库系统进行通信。
关系数据库由表、行和列组成。列通常具有类型,例如文本、数字或日期数据。当我们创建表时,我们指定列的名称和类型:
CREATE TABLE Track (title TEXT, plays INTEGER)
要向表中插入一行,我们使用 SQL INSERT 命令:
INSERT INTO Track (title, plays) VALUES ('My Way', 15)
INSERT 语句指定表名,然后是要在新行中设置的字段/列列表,接着是关键字 VALUES 和每个字段对应的列表。
SQL SELECT 命令用于从数据库中检索行和列。SELECT 语句允许你指定想要检索的列,以及一个 WHERE 子句来选择你想要看到的行。它还允许一个可选的 ORDER BY 子句来控制返回行的排序。
SELECT * FROM Track WHERE title = 'My Way'
使用 * 表示你希望数据库返回匹配 WHERE 子句的每一行的所有列。
请注意,与 Python 不同,在 SQL WHERE 子句中,我们使用单个等号来表示相等性测试,而不是双等号。WHERE 子句中允许的其他逻辑运算包括 <、>、<=、>=、!=,以及 AND 和 OR 与括号来构建你的逻辑表达式。
你可以请求按某个字段对返回的行进行排序,如下所示:
SELECT title,plays FROM Track ORDER BY title
可以使用 SQL UPDATE 语句更新表中一个或多个行中的一个或多个列,如下所示:
UPDATE Track SET plays = 16 WHERE title = 'My Way'
UPDATE 语句指定一个表,然后在 SET 关键字后跟一个要更改的字段和值列表,然后是一个可选的 WHERE 子句来选择要更新的行。单个 UPDATE 语句将更改所有匹配 WHERE 子句的行。如果未指定 WHERE 子句,它将对表中的所有行执行 UPDATE。
要移除一行,你需要在 SQL DELETE 语句上使用 WHERE 子句。WHERE 子句确定要删除哪些行:
DELETE FROM Track WHERE title = 'My Way'
这四个基本的 SQL 命令(INSERT、SELECT、UPDATE 和 DELETE)允许创建和维护数据所需的四种基本操作。我们使用 “CRUD”(Create, Read, Update, and Delete - 创建、读取、更新和删除)来用一个术语概括所有这些概念。2
多表和基本数据建模
关系数据库的真正威力在于我们创建多个表并在这些表之间建立链接。决定如何将应用程序数据分解为多个表并建立表之间关系的行为称为数据建模 (data modeling)。显示表及其关系的设计文档称为数据模型 (data model)。
数据建模是一项相对复杂的技能,在本节中我们只会介绍关系数据建模的最基本概念。有关数据建模的更多详细信息,你可以从以下内容开始:
http://en.wikipedia.org/wiki/Relational_model
假设对于我们的曲目数据库,除了每首曲目的 title 和播放次数 plays 之外,我们还想跟踪每首曲目的 artist 姓名。一个简单的方法可能只是向数据库添加一个名为 artist 的列,并将艺术家的姓名放入该列中,如下所示:
DROP TABLE IF EXISTS Track;
CREATE TABLE Track (title TEXT, plays INTEGER, artist TEXT);
然后我们可以在表中插入几条曲目。
INSERT INTO Track (title, plays, artist)
VALUES ('My Way', 15, 'Frank Sinatra');
INSERT INTO Track (title, plays, artist)
VALUES ('New York', 25, 'Frank Sinatra');
如果我们使用 SELECT * FROM Track 语句查看我们的数据,看起来我们做得很好。
sqlite> SELECT * FROM Track;
My Way|15|Frank Sinatra
New York|25|Frank Sinatra
sqlite>
我们在数据建模中犯了一个非常严重的错误。我们违反了数据库规范化 (database normalization) 的规则。
https://en.wikipedia.org/wiki/Database_normalization
虽然数据库规范化表面上看起来非常复杂,并且包含许多数学论证,但现在我们可以将其简化为我们将遵循的一条简单规则。
我们永远不应该将相同的字符串数据多次放入同一列中。如果我们需要多次使用该数据,我们应该为该数据创建一个数字键 (key),并使用此键引用实际数据。特别是当多个条目引用同一个对象时。
为了演示我们在数据库模型中分配字符串列所走的下坡路,想一想如果我们想跟踪艺术家的眼睛颜色,我们将如何更改数据模型?我们会这样做吗?
DROP TABLE IF EXISTS Track;
CREATE TABLE Track (title TEXT, plays INTEGER,
artist TEXT, eyes TEXT);
INSERT INTO Track (title, plays, artist, eyes)
VALUES ('My Way', 15, 'Frank Sinatra', 'Blue');
INSERT INTO Track (title, plays, artist, eyes)
VALUES ('New York', 25, 'Frank Sinatra', 'Blue');
由于弗兰克·辛纳屈录制了超过 1200 首歌曲,我们真的要在 Track 表的 1200 行中放入字符串 ‘Blue’ 吗?如果我们决定他的眼睛颜色是 ‘Light Blue’,会发生什么?感觉有点不对劲。
正确的解决方案是为每个 Artist 创建一个表,并将关于该艺术家的所有数据存储在该表中。然后我们需要某种方式在 Track 表中的行和 Artist 表中的行之间建立连接。也许我们可以称这个两个“表”之间的“链接”为两个表之间的“关系”。这正是数据库专家决定称呼这些链接的方式。
让我们创建一个 Artist 表,如下所示:
DROP TABLE IF EXISTS Artist;
CREATE TABLE Artist (name TEXT, eyes TEXT);
INSERT INTO Artist (name, eyes)
VALUES ('Frank Sinatra', 'blue');
现在我们有两个表,但我们需要一种方法来链接两个表中的行。为此,我们需要所谓的“键”。这些键只是整数,我们可以用它们来查找不同表中的行。如果我们要建立指向表中行的链接,我们需要向表中的行添加一个主键 (primary key)。按照惯例,我们通常将主键列命名为 ‘id’。所以我们的 Artist 表看起来如下:
DROP TABLE IF EXISTS Artist;
CREATE TABLE Artist (id INTEGER, name TEXT, eyes TEXT);
INSERT INTO Artist (id, name, eyes)
VALUES (42, 'Frank Sinatra', 'blue');
现在我们在表中有一行代表 ‘Frank Sinatra’(以及他的眼睛颜色),并有一个主键 ‘42’ 用于将我们的曲目链接到他。所以我们像下面这样修改我们的 Track 表:
DROP TABLE IF EXISTS Track;
CREATE TABLE Track (title TEXT, plays INTEGER,
artist_id INTEGER);
INSERT INTO Track (title, plays, artist_id)
VALUES ('My Way', 15, 42);
INSERT INTO Track (title, plays, artist_id)
VALUES ('New York', 25, 42);
artist_id 列是一个整数,按照命名约定,它是一个外键 (foreign key),指向 Artist 表中的主键。我们称它为外键,因为它指向另一个表中的行。
现在我们遵循了数据库规范化的规则,但是当我们想从数据库中获取数据时,我们不想看到 42,我们想看到艺术家的姓名和眼睛颜色。为此,我们在 SELECT 语句中使用 JOIN 关键字。
SELECT title, plays, name, eyes
FROM Track JOIN Artist
ON Track.artist_id = Artist.id;
JOIN 子句包含一个 ON 条件,该条件定义了行应如何连接。对于 Track 中的每一行,从 Artist 中添加数据,条件是 Track 表中的 artist_id 与 Artist 表中的 id 匹配。
输出将是:
My Way|15|Frank Sinatra|blue
New York|25|Frank Sinatra|blue
虽然这看起来可能有点笨拙,你的直觉可能会告诉你将数据保存在一个表中会更快,但事实证明数据库性能的限制在于检索查询时需要扫描多少数据。虽然细节非常复杂,但整数比字符串(尤其是 Unicode)小得多,移动和比较起来也快得多。
数据模型图
虽然我们的 Track 和 Artist 数据库设计只有两个表和一个简单的一对多关系,但这些数据模型会很快变得复杂,如果我们能制作数据模型的图形表示,就更容易理解。
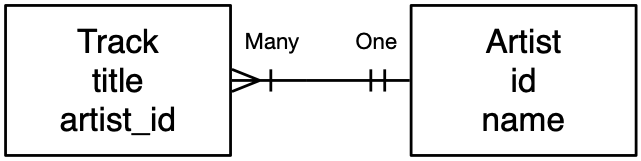 一个详细的一对多数据模型
一个详细的一对多数据模型
虽然数据模型有许多图形表示法,但我们将使用一种“经典”方法,称为“鸦脚图”(Crow’s Foot Diagrams),如图 figure 所示。每个表都显示为一个框,其中包含表名及其列。然后在两个表之间存在关系的地方绘制一条连接线,并在每条线的末端添加注释,指示关系的性质。
https://en.wikipedia.org/wiki/Entity-relationship_model
在这种情况下,“许多”曲目可以与每个艺术家相关联。所以曲目端用展开的鸦脚表示,表明它是“多”端。艺术家端用一条竖线表示,表明是“一”端。通常会有“许多”艺术家,但重要的是,对于每个艺术家,会有许多曲目。而每个艺术家可能与多个曲目相关联。
你会注意到持有外键(如 artist_id)的列在“多”端,而主键在“一”端。
由于外键和主键的放置模式如此一致,并且遵循线的“多”和“一”端,我们从不在数据模型图中包含主键或外键列,如第二个图 figure 所示。这些列被认为是“实现细节”,用于捕获关系细节的本质,而不是被建模数据的重要组成部分。
 一个简洁的一对多数据模型
一个简洁的一对多数据模型
自动创建主键
在上面的例子中,我们任意地将弗兰克的主键指定为 42。然而,当我们要插入数百万行时,让数据库自动生成 id 列的值会很方便。我们通过将 id 列声明为 PRIMARY KEY 并在插入行时省略 id 值来实现这一点:
DROP TABLE IF EXISTS Artist;
CREATE TABLE Artist (id INTEGER PRIMARY KEY,
name TEXT, eyes TEXT);
INSERT INTO Artist (name, eyes)
VALUES ('Frank Sinatra', 'blue');
现在我们已经指示数据库自动为弗兰克·辛纳屈的行分配一个唯一的值。但是我们需要一种方法让数据库告诉我们最近插入行的 id 值。一种方法是使用 SELECT 语句从名为 last_insert_rowid() 的 SQLite 内置函数中检索数据。
sqlite> DROP TABLE IF EXISTS Artist;
sqlite> CREATE TABLE Artist (id INTEGER PRIMARY KEY,
...> name TEXT, eyes TEXT);
sqlite> INSERT INTO Artist (name, eyes)
...> VALUES ('Frank Sinatra', 'blue');
sqlite> select last_insert_rowid();
1
sqlite> SELECT * FROM Artist;
1|Frank Sinatra|blue
sqlite>
一旦我们知道了 ‘Frank Sinatra’ 行的 id,我们就可以在向 Track 表 INSERT 曲目时使用它。作为通用策略,我们将这些 id 列添加到我们创建的任何表中:
sqlite> DROP TABLE IF EXISTS Track;
sqlite> CREATE TABLE Track (id INTEGER PRIMARY KEY,
...> title TEXT, plays INTEGER, artist_id INTEGER);
请注意,artist_id 值是 Artist 表中新自动分配的行,并且虽然我们向 Track 表添加了 INTEGER PRIMARY KEY,但我们没有在 Track 表的 INSERT 语句的字段列表中包含 id。这再次告诉数据库为我们为 id 列选择一个唯一的值。
sqlite> INSERT INTO Track (title, plays, artist_id)
...> VALUES ('My Way', 15, 1);
sqlite> select last_insert_rowid();
1
sqlite> INSERT INTO Track (title, plays, artist_id)
...> VALUES ('New York', 25, 1);
sqlite> select last_insert_rowid();
2
sqlite>
你可以在每次插入后调用 SELECT last_insert_rowid(); 来检索数据库为每个新创建的行分配给 id 的值。稍后当我们在 Python 中编码时,我们可以在代码中请求 id 值并将其存储在变量中以供后续使用。
用于快速查找的逻辑键
如果我们有一个充满艺术家的表和一个充满曲目的表,每个曲目都通过外键链接到艺术家表中的一行,并且我们想列出所有由 ‘Frank Sinatra’ 演唱的曲目,如下所示:
SELECT title, plays, name, eyes
FROM Track JOIN Artist
ON Track.artist_id = Artist.id
WHERE Artist.name = 'Frank Sinatra';
由于我们有两个表并且两个表之间有外键,我们的数据模型是良好的,但是如果 Artist 表中将有数百万条记录,并且我们将要根据艺术家姓名进行大量查找,那么如果我们给数据库一个关于我们打算使用 name 列的提示,将会受益匪浅。
我们通过向我们打算在 WHERE 子句中使用的文本列添加一个“索引”来实现这一点:
CREATE INDEX artist_name ON Artist(name);
当数据库被告知需要在表的某个列上创建索引时,它会存储额外的信息,以便能够使用索引字段(本例中为 name)更快速地查找行。一旦你请求创建索引,就不需要在 SQL 中进行任何特殊操作来访问该表。数据库会在插入、删除和更新数据时保持索引最新,并且如果索引能提高数据库查询性能,数据库会自动使用它。
这些用于根据“现实世界”中的某些信息(如艺术家姓名)查找行的文本列称为逻辑键 (Logical keys)。
向数据库添加约束
我们还可以使用索引来强制执行数据库操作的约束 (constraint)(即规则)。最常见的约束是唯一性约束 (uniqueness constraint),它要求列中的所有值都是唯一的。我们可以在 CREATE INDEX 语句中添加可选的 UNIQUE 关键字,告诉数据库我们希望它对我们的 SQL 强制执行该约束。我们可以删除并重新创建带有 UNIQUE 约束的 artist_name 索引,如下所示。
DROP INDEX artist_name;
CREATE UNIQUE INDEX artist_name ON Artist(name);
如果我们尝试第二次插入 ‘Frank Sinatra’,它将失败并报错。
sqlite> SELECT * FROM Artist;
1|Frank Sinatra|blue
sqlite> INSERT INTO Artist (name, eyes)
...> VALUES ('Frank Sinatra', 'blue');
Runtime error: UNIQUE constraint failed: Artist.name (19)
sqlite>
我们可以通过在 INSERT 语句中添加 IGNORE 关键字来告诉数据库忽略任何重复键错误,如下所示:
sqlite> INSERT OR IGNORE INTO Artist (name, eyes)
...> VALUES ('Frank Sinatra', 'blue');
sqlite> SELECT id FROM Artist WHERE name='Frank Sinatra';
1
sqlite>
通过结合 INSERT OR IGNORE 和 SELECT,我们可以在名称不存在时插入新记录,并且无论记录是否已存在,都可以检索记录的主键。
sqlite> INSERT OR IGNORE INTO Artist (name, eyes)
...> VALUES ('Elvis', 'blue');
sqlite> SELECT id FROM Artist WHERE name='Elvis';
2
sqlite> SELECT * FROM Artist;
1|Frank Sinatra|blue
2|Elvis|blue
sqlite>
由于我们没有为眼睛颜色列添加唯一性约束,因此在 eye 列中有多个 ‘Blue’ 值是没有问题的。
 曲目、专辑和艺术家
曲目、专辑和艺术家
多表示例应用程序
一个名为 tracks_csv.py 的示例应用程序展示了如何将这些思想结合起来,解析文本数据并将其加载到多个表中,使用具有表间关系连接的正确数据模型。
此应用程序读取并解析基于 Dr. Chuck 的 iTunes 库导出的逗号分隔文件 tracks.csv。
Another One Bites The Dust,Queen,Greatest Hits,55,100,217103
Asche Zu Asche,Rammstein,Herzeleid,79,100,231810
Beauty School Dropout,Various,Grease,48,100,239960
Black Dog,Led Zeppelin,IV,109,100,296620
...
此文件中的列是:标题、艺术家、专辑、播放次数、评分(0-100)和以毫秒为单位的长度。
我们的数据模型如图 figure 所示,并用 SQL 描述如下:
DROP TABLE IF EXISTS Artist;
DROP TABLE IF EXISTS Album;
DROP TABLE IF EXISTS Track;
CREATE TABLE Artist (
id INTEGER PRIMARY KEY,
name TEXT UNIQUE
);
CREATE TABLE Album (
id INTEGER PRIMARY KEY,
artist_id INTEGER,
title TEXT UNIQUE
);
CREATE TABLE Track (
id INTEGER PRIMARY KEY,
title TEXT UNIQUE,
album_id INTEGER,
len INTEGER, rating INTEGER, count INTEGER
);
我们正在向我们希望具有唯一性约束的 TEXT 列添加 UNIQUE 关键字,我们将在 INSERT IGNORE 语句中使用该约束。这比单独的 CREATE INDEX 语句更简洁,但效果相同。
有了这些表之后,我们编写以下代码 tracks_csv.py 来解析数据并将其插入到表中:
import sqlite3
conn = sqlite3.connect('trackdb.sqlite')
cur = conn.cursor()
handle = open('tracks.csv')
for line in handle:
line = line.strip();
pieces = line.split(',')
if len(pieces) != 6 : continue
name = pieces[0]
artist = pieces[1]
album = pieces[2]
count = pieces[3]
rating = pieces[4]
length = pieces[5]
print(name, artist, album, count, rating, length)
cur.execute('''INSERT OR IGNORE INTO Artist (name)
VALUES ( ? )''', ( artist, ) )
cur.execute('SELECT id FROM Artist WHERE name = ? ', (artist, ))
artist_id = cur.fetchone()[0]
cur.execute('''INSERT OR IGNORE INTO Album (title, artist_id)
VALUES ( ?, ? )''', ( album, artist_id ) )
cur.execute('SELECT id FROM Album WHERE title = ? ', (album, ))
album_id = cur.fetchone()[0]
cur.execute('''INSERT OR REPLACE INTO Track
(title, album_id, len, rating, count)
VALUES ( ?, ?, ?, ?, ? )''',
( name, album_id, length, rating, count ) )
conn.commit()
你可以看到我们正在重复 INSERT OR IGNORE 后跟 SELECT 的模式,以获取适当的 artist_id 和 album_id 用于后续的 INSERT 语句。我们从 Artist 开始,因为我们需要 artist_id 来插入 Album,需要 album_id 来插入 Track。
如果我们查看 Album 表,可以看到条目已根据需要添加并分配了主键,因为数据已被解析。我们还可以看到每个 Album 行都指向 Artist 表中行的外键。
sqlite> .mode column
sqlite> SELECT * FROM Album LIMIT 5;
id artist_id title
-- --------- -----------------
1 1 Greatest Hits
2 2 Herzeleid
3 3 Grease
4 4 IV
5 5 The Wall [Disc 2]
我们可以使用 JOIN / ON 子句来重构所有 Track 数据,遵循所有关系。你可以在下面的输出中看到每个关系连接(共 2 个)的两端:
sqlite> .mode line
sqlite> SELECT * FROM Track
...> JOIN Album ON Track.album_id = Album.id
...> JOIN Artist ON Album.artist_id = Artist.id
...> LIMIT 2;
id = 1
title = Another One Bites The Dust
album_id = 1
len = 217103
rating = 100
count = 55
id = 1
artist_id = 1
title = Greatest Hits
id = 1
name = Queen
id = 2
title = Asche Zu Asche
album_id = 2
len = 231810
rating = 100
count = 79
id = 2
artist_id = 2
title = Herzeleid
id = 2
name = Rammstein
这个例子展示了三个表和表之间的两个一对多关系。它还展示了如何使用索引和唯一性约束以编程方式构建表及其关系。
https://en.wikipedia.org/wiki/One-to-many_(data_model)
接下来我们将看看数据模型中的多对多关系。
数据库中的多对多关系
有些数据关系不能用简单的一对多关系来建模。例如,假设我们要为一个课程管理系统构建数据模型。将有课程、用户和花名册。一个用户可以在多个课程的花名册上,一个课程的花名册上也会有多个用户。
绘制一个多对多关系非常简单,如图 figure 所示。我们只需绘制两个表,并用一条线连接它们,线的两端都带有“多”的指示符。问题在于如何使用主键和外键实现这种关系。
在我们探索如何实现多对多关系之前,让我们看看是否可以通过扩展一对多关系来拼凑出一些东西。
 多对多关系
多对多关系
如果 SQL 支持数组的概念,我们可能会尝试定义这个:
CREATE TABLE Course (
id INTEGER PRIMARY KEY,
title TEXT UNIQUE
student_ids ARRAY OF INTEGER;
);
遗憾的是,虽然这是一个诱人的想法,但 SQL 不支持数组。3
或者我们可以只制作一个长字符串,并将所有 User 主键连接成一个用逗号分隔的长字符串。
CREATE TABLE Course (
id INTEGER PRIMARY KEY,
title TEXT UNIQUE
student_ids ARRAY OF INTEGER;
);
INSERT INTO Course (title, student_ids)
VALUES( 'si311', '1,3,4,5,6,9,14');
这将非常低效,因为随着课程花名册规模的增长和课程数量的增加,找出哪些课程的花名册上有学生 14 会变得相当昂贵。
 多对多连接表
多对多连接表
我们不采用这两种方法,而是使用一个额外的表来建模多对多关系,我们称之为“连接表”(junction table)、“穿梭表”(through table)、“连接器表”(connector table) 或“联接表”(join table),如图 figure 所示。这个表的目的是捕获一个课程和一个学生之间的连接。
从某种意义上说,该表位于 Course 和 User 表之间,并且与这两个表都存在一对多关系。通过使用中间表,我们将一个多对多关系分解为两个一对多关系。数据库非常擅长建模和处理一对多关系。
一个示例 Member 表如下所示:
CREATE TABLE User (
id INTEGER PRIMARY KEY,
name TEXT UNIQUE
);
CREATE TABLE Course (
id INTEGER PRIMARY KEY,
title TEXT UNIQUE
);
CREATE TABLE Member (
user_id INTEGER,
course_id INTEGER,
PRIMARY KEY (user_id, course_id)
);
遵循我们的命名约定,Member.user_id 和 Member.course_id 是指向 User 和 Course 表中相应行的外键。成员表中的每个条目都通过 Member 表将 User 表中的一行链接到 Course 表中的一行。
我们指示 course_id 和 user_id 的组合是 Member 表的 PRIMARY KEY,同时也为 course_id / user_id 组合创建了唯一性约束。
现在假设我们需要将一些学生插入到一些课程的花名册中。假设数据以 JSON 格式的文件提供给我们,记录如下:
[
[ "Charley", "si110"],
[ "Mea", "si110"],
[ "Hattie", "si110"],
[ "Keziah", "si110"],
[ "Rosa", "si106"],
[ "Mea", "si106"],
[ "Mairin", "si106"],
[ "Zendel", "si106"],
[ "Honie", "si106"],
[ "Rosa", "si106"],
...
]
我们可以编写如下代码来读取 JSON 文件并将每个课程花名册的成员插入数据库:
import json
import sqlite3
conn = sqlite3.connect('rosterdb.sqlite')
cur = conn.cursor()
str_data = open('roster_data_sample.json').read()
json_data = json.loads(str_data)
for entry in json_data:
name = entry[0]
title = entry[1]
print((name, title))
cur.execute('''INSERT OR IGNORE INTO User (name)
VALUES ( ? )''', ( name, ) )
cur.execute('SELECT id FROM User WHERE name = ? ', (name, ))
user_id = cur.fetchone()[0]
cur.execute('''INSERT OR IGNORE INTO Course (title)
VALUES ( ? )''', ( title, ) )
cur.execute('SELECT id FROM Course WHERE title = ? ', (title, ))
course_id = cur.fetchone()[0]
cur.execute('''INSERT OR REPLACE INTO Member
(user_id, course_id) VALUES ( ?, ? )''',
( user_id, course_id ) )
conn.commit()
像之前的例子一样,我们首先确保 User 表中有一个条目并知道该条目的主键,以及 Course 表中有一个条目并知道其主键。我们使用 ‘INSERT OR IGNORE’ 和 ‘SELECT’ 模式,这样无论记录是否在表中,我们的代码都能工作。
我们对 Member 表的插入只是简单地插入两个整数作为新行或现有行,具体取决于约束,以确保我们最终不会在 Member 表中为特定的 user_id / course_id 组合得到重复的条目。
为了跨所有三个表重构我们的数据,我们再次使用 JOIN / ON 来构建 SELECT 查询;
sqlite> SELECT * FROM Course
...> JOIN Member ON Course.id = Member.course_id
...> JOIN User ON Member.user_id = User.id;
+----+-------+---------+-----------+----+---------+
| id | title | user_id | course_id | id | name |
+----+-------+---------+-----------+----+---------+
| 1 | si110 | 1 | 1 | 1 | Charley |
| 1 | si110 | 2 | 1 | 2 | Mea |
| 1 | si110 | 3 | 1 | 3 | Hattie |
| 1 | si110 | 4 | 1 | 4 | Lyena |
| 1 | si110 | 5 | 1 | 5 | Keziah |
| 1 | si110 | 6 | 1 | 6 | Ellyce |
| 1 | si110 | 7 | 1 | 7 | Thalia |
| 1 | si110 | 8 | 1 | 8 | Meabh |
| 2 | si106 | 2 | 2 | 2 | Mea |
| 2 | si106 | 10 | 2 | 10 | Mairin |
| 2 | si106 | 11 | 2 | 11 | Zendel |
| 2 | si106 | 12 | 2 | 12 | Honie |
| 2 | si106 | 9 | 2 | 9 | Rosa |
+----+-------+---------+-----------+----+---------+
sqlite>
你可以看到从左到右的三个表 - Course、Member 和 User,并且你可以在输出的每一行中看到主键和外键之间的连接。
在多对多连接处建模数据
虽然我们已经将“连接表”呈现为具有两个外键,在两个表的行之间建立连接,但这只是连接表最简单的形式。通常希望在连接本身上添加一些数据。
继续我们用户、课程和花名册的例子来建模一个简单的学习管理系统,我们还需要了解每个用户在每门课程中被分配的角色 (role)。
如果我们首先尝试通过向 User 表添加一个“instructor”标志来解决这个问题,我们会发现这行不通,因为一个用户可能在一门课程中是讲师,而在另一门课程中是学生。如果我们在 Course 表中添加一个 instructor_id,它也行不通,因为一门课程可以有多个讲师。而且没有一对多的技巧可以处理角色数量将扩展到助教或家长等角色的事实。
但是,如果我们简单地向 Member 表添加一个 role 列 - 我们就可以表示各种各样的角色、角色组合等。
让我们像下面这样更改我们的成员表:
DROP TABLE Member;
CREATE TABLE Member (
user_id INTEGER,
course_id INTEGER,
role INTEGER,
PRIMARY KEY (user_id, course_id)
);
为简单起见,我们将规定角色中的零表示“学生”,一表示“讲师”。假设我们的 JSON 数据增加了角色信息,如下所示:
[
[ "Charley", "si110", 1],
[ "Mea", "si110", 0],
[ "Hattie", "si110", 0],
[ "Keziah", "si110", 0],
[ "Rosa", "si106", 0],
[ "Mea", "si106", 1],
[ "Mairin", "si106", 0],
[ "Zendel", "si106", 0],
[ "Honie", "si106", 0],
[ "Rosa", "si106", 0],
...
]
我们可以修改上面的 roster.py 程序以包含角色,如下所示:
for entry in json_data:
name = entry[0]
title = entry[1]
role = entry[2]
...
cur.execute('''INSERT OR REPLACE INTO Member
(user_id, course_id, role) VALUES ( ?, ?, ? )''',
( user_id, course_id, role ) )
在一个真实的系统中,我们可能会构建一个 Role 表,并将 Member 中的 role 列设为指向 Role 表的外键,如下所示:
DROP TABLE Member;
CREATE TABLE Member (
user_id INTEGER,
course_id INTEGER,
role_id INTEGER,
PRIMARY KEY (user_id, course_id, role_id)
);
CREATE TABLE Role (
id INTEGER PRIMARY KEY,
name TEXT UNIQUE
);
INSERT INTO Role (id, name) VALUES (0, 'Student');
INSERT INTO Role (id, name) VALUES (1, 'Instructor');
请注意,因为我们在 Role 表中将 id 列声明为 PRIMARY KEY,所以我们可以在 INSERT 语句中省略它。但我们也可以选择 id 值,只要该值在 id 列中尚不存在并且不违反主键上隐含的 UNIQUE 约束。
总结
本章涵盖了很多内容,为你概述了在 Python 中使用数据库的基础知识。编写使用数据库存储数据的代码比使用 Python 字典或平面文件更复杂,因此除非你的应用程序真正需要数据库的功能,否则几乎没有理由使用数据库。数据库可能非常有用的情况是:(1)当你的应用程序需要在大型数据集中进行许多小的随机更新时,(2)当你的数据量太大而无法放入字典中,并且你需要重复查找信息时,或者(3)当你有一个长期运行的进程,希望能够停止和重新启动,并保留从一次运行到下一次运行的数据时。
你可以构建一个包含单个表的简单数据库来满足许多应用程序的需求,但大多数问题将需要多个表以及不同表中行之间的链接/关系。当你开始在表之间建立链接时,进行一些深思熟虑的设计并遵循数据库规范化规则以充分利用数据库的功能非常重要。由于使用数据库的主要动机是你需要处理大量数据,因此高效地建模你的数据以使你的程序运行尽可能快非常重要。
调试
当你开发连接到 SQLite 数据库的 Python 程序时,一个常见的模式是运行 Python 程序并使用 SQLite 数据库浏览器检查结果。浏览器允许你快速检查你的程序是否正常工作。
你必须小心,因为 SQLite 会注意防止两个程序同时更改相同的数据。例如,如果你在浏览器中打开一个数据库并对数据库进行了更改,但尚未在浏览器中按下“保存”按钮,则浏览器会“锁定”数据库文件,并阻止任何其他程序访问该文件。特别是,如果数据库文件被锁定,你的 Python 程序将无法访问该文件。
因此,一个解决方案是确保在尝试从 Python 访问数据库之前,要么关闭数据库浏览器,要么使用浏览器的“文件”菜单关闭数据库,以避免你的 Python 代码因数据库被锁定而失败的问题。
术语表
属性 (attribute) 元组中的值之一。更通常称为“列”或“字段”。 约束 (constraint) 当我们告诉数据库对表中的字段或行强制执行规则时。一个常见的约束是坚持特定字段中不能有重复值(即所有值必须是唯一的)。 游标 (cursor) 游标允许你在数据库中执行 SQL 命令并从数据库中检索数据。游标类似于用于网络连接和文件的套接字或文件句柄。 数据库浏览器 (database browser) 一种允许你直接连接到数据库并直接操作数据库而无需编写程序的软件。 外键 (foreign key) 指向另一个表中行的主键的数字键。外键在存储在不同表中的行之间建立关系。 索引 (index) 数据库软件在表中插入行时维护的额外数据,用于使查找非常快速。 逻辑键 (logical key) “外部世界”用于查找特定行的键。例如,在用户帐户表中,一个人的电子邮件地址可能是用户数据逻辑键的良好候选者。 规范化 (normalization) 设计数据模型以便不复制任何数据。我们将每个数据项存储在数据库中的一个位置,并在其他地方使用外键引用它。 主键 (primary key) 分配给每一行的数字键,用于从另一个表引用表中的一行。通常数据库被配置为在插入行时自动分配主键。 关系 (relation) 数据库中包含元组和属性的区域。更通常称为“表”。 元组 (tuple) 数据库表中的单个条目,它是一组属性。更通常称为“行”。
- SQLite 实际上在存储在列中的数据类型方面允许一定的灵活性,但我们将在本章中保持我们的数据类型严格,以便这些概念同样适用于其他数据库系统,例如 MySQL。↩︎
- 是的,“CRUD”术语与实现“CRUD”的四个 SQL 语句的首字母之间存在脱节。一个可能的解释可能是声称“CRUD”是“概念”,而 SQL 是实现。另一个可能的解释是“CRUD”比“ISUD”说起来更有趣。↩︎
- 一些 SQL 方言支持数组,但数组的可伸缩性不好。NoSQL 数据库使用数组和数据复制,但以牺牲数据库完整性为代价。NoSQL 是另一门课程的故事 https://www.pg4e.com/ ↩︎
如果你在本书中发现错误,欢迎使用 Github 给我发送修正。