可视化数据
到目前为止,我们一直在学习 Python 语言,然后学习如何使用 Python、网络和数据库来处理数据。
在本章中,我们将看三个完整的应用程序,它们将所有这些内容结合起来管理和可视化数据。你可以将这些应用程序用作示例代码,以帮助你开始解决实际问题。
每个应用程序都是一个 ZIP 文件,你可以下载并解压缩到你的计算机上并执行。
从地理编码数据构建 OpenStreetMap
在这个项目中,我们使用 OpenStreetMap 地理编码 API 来清理一些用户输入的大学名称的地理位置,然后将数据放置在实际的 OpenStreetMap 上。
 一个 OpenStreetMap 地图
一个 OpenStreetMap 地图
要开始,请从以下地址下载应用程序:
www.py4e.com/code3/opengeo.zip
首先要解决的问题是,这些地理编码 API 每天都有请求次数的速率限制。如果你有大量数据,你可能需要多次停止和重新启动查找过程。所以我们将问题分解为两个阶段。
在第一阶段,我们获取文件 where.data 中的输入“调查”数据,并逐行读取,从 Google 检索地理编码信息并将其存储在数据库 geodata.sqlite 中。在我们为每个用户输入的位置使用地理编码 API 之前,我们只需检查是否已经有该特定输入行的数据。数据库充当了我们地理编码数据的本地“缓存”,以确保我们永远不会两次向 Google 请求相同的数据。
你可以随时通过删除文件 geodata.sqlite 来重新启动该过程。
运行 geoload.py 程序。这个程序将读取 where.data 中的输入行,并对每一行检查它是否已在数据库中。如果我们没有该位置的数据,它将调用地理编码 API 来检索数据并将其存储在数据库中。
下面是在数据库中已有部分数据后的示例运行:
在数据库中找到 AGH University of Science and Technology
在数据库中找到 Academy of Fine Arts Warsaw Poland
在数据库中找到 American University in Cairo
在数据库中找到 Arizona State University
在数据库中找到 Athens Information Technology
正在检索 https://py4e-data.dr-chuck.net/
opengeo?q=BITS+Pilani
检索到 794 个字符 {"type":"FeatureColl
正在检索 https://py4e.com/data3/
opengeo?q=Babcock+University
检索到 760 个字符 {"type":"FeatureColl
正在检索 https://py4e.com/data3/
opengeo?q=Banaras+Hindu+University
检索到 866 个字符 {"type":"FeatureColl
...
前五个位置已经在数据库中,因此它们被跳过。程序扫描到找到新位置的点并开始检索它们。
geoload.py 程序可以随时停止,并且有一个计数器,你可以用它来限制每次运行对地理编码 API 的调用次数。鉴于 where.data 只有几百个数据项,你应该不会遇到每日速率限制,但如果你有更多数据,可能需要几天内运行几次才能让你的数据库包含所有输入的地理编码数据。
一旦你将一些数据加载到 geodata.sqlite 中,你就可以使用 geodump.py 程序来可视化数据。这个程序读取数据库并将位置、纬度和经度以可执行 JavaScript 代码的形式写入文件 where.js。
geodump.py 程序的一次运行如下:
AGH University of Science and Technology, Czarnowiejska,
Czarna Wieś, Krowodrza, Kraków, Lesser Poland
Voivodeship, 31-126, Poland 50.0657 19.91895
Academy of Fine Arts, Krakowskie Przedmieście,
Northern Śródmieście, Śródmieście, Warsaw, Masovian
Voivodeship, 00-046, Poland 52.239 21.0155
...
260 行已写入 where.js
在网络浏览器中打开 where.html 文件以查看数据。
文件 where.html 包含用于可视化 Google 地图的 HTML 和 JavaScript。它读取 where.js 中的最新数据以获取要可视化的数据。以下是 where.js 文件的格式:
myData = [
[50.0657,19.91895,
'AGH University of Science and Technology, Czarnowiejska,
Czarna Wieś, Krowodrza, Kraków, Lesser Poland
Voivodeship, 31-126, Poland '],
[52.239,21.0155,
'Academy of Fine Arts, Krakowskie Przedmieściee,
Śródmieście Północne, Śródmieście, Warsaw,
Masovian Voivodeship, 00-046, Poland'],
...
];
这是一个包含列表的列表的 JavaScript 变量。JavaScript 列表常量的语法与 Python 非常相似,所以你应该熟悉这个语法。
只需在浏览器中打开 where.html 即可查看位置。你可以将鼠标悬停在每个地图图钉上,以查找地理编码 API 为用户输入返回的位置。如果你在打开 where.html 文件时看不到任何数据,你可能需要检查浏览器的 JavaScript 或开发者控制台。
可视化网络和互连
在这个应用程序中,我们将执行搜索引擎的一些功能。我们将首先爬取网络的一个小子集,并运行简化版的 Google PageRank 算法来确定哪些页面连接最紧密,然后可视化我们这个小角落网络的页面排名和连接性。我们将使用 D3 JavaScript 可视化库 http://d3js.org/ 来生成可视化输出。
你可以从以下地址下载并解压缩此应用程序:
www.py4e.com/code3/pagerank.zip
 一个 PageRank 可视化
一个 PageRank 可视化
第一个程序 (spider.py) 爬取一个网站并将一系列页面拉入数据库 (spider.sqlite),记录页面之间的链接。你可以随时通过删除 spider.sqlite 文件并重新运行 spider.py 来重新启动该过程。
输入网址或回车:http://www.dr-chuck.com/
['http://www.dr-chuck.com']
多少页:2
1 http://www.dr-chuck.com/ 12
2 http://www.dr-chuck.com/csev-blog/ 57
多少页:
在这个示例运行中,我们告诉它爬取一个网站并检索两个页面。如果你重新启动程序并告诉它爬取更多页面,它不会重新爬取任何已经在数据库中的页面。重新启动时,它会转到一个随机的未爬取页面并从那里开始。所以 spider.py 的每次后续运行都是累加的。
输入网址或回车:http://www.dr-chuck.com/
['http://www.dr-chuck.com']
多少页:3
3 http://www.dr-chuck.com/csev-blog 57
4 http://www.dr-chuck.com/dr-chuck/resume/speaking.htm 1
5 http://www.dr-chuck.com/dr-chuck/resume/index.htm 13
多少页:
你可以在同一个数据库中有多个起始点——在程序中,这些被称为“网络”(webs)。爬虫在所有网络中所有未访问的链接中随机选择下一个要爬取的页面。
如果你想转储 spider.sqlite 文件的内容,可以运行 spdump.py,如下所示:
(5, None, 1.0, 3, 'http://www.dr-chuck.com/csev-blog')
(3, None, 1.0, 4, 'http://www.dr-chuck.com/dr-chuck/resume/speaking.htm')
(1, None, 1.0, 2, 'http://www.dr-chuck.com/csev-blog/')
(1, None, 1.0, 5, 'http://www.dr-chuck.com/dr-chuck/resume/index.htm')
4 行。
这显示了入链数、旧的 PageRank、新的 PageRank、页面 ID 和页面 URL。spdump.py 程序仅显示至少有一个入链指向它们的页面。
一旦数据库中有了一些页面,你就可以使用 sprank.py 程序在这些页面上运行 PageRank。你只需告诉它要运行多少次 PageRank 迭代。
多少次迭代:2
1 0.546848992536
2 0.226714939664
[(1, 0.559), (2, 0.659), (3, 0.985), (4, 2.135), (5, 0.659)]
你可以再次转储数据库以查看 PageRank 已更新:
(5, 1.0, 0.985, 3, 'http://www.dr-chuck.com/csev-blog')
(3, 1.0, 2.135, 4, 'http://www.dr-chuck.com/dr-chuck/resume/speaking.htm')
(1, 1.0, 0.659, 2, 'http://www.dr-chuck.com/csev-blog/')
(1, 1.0, 0.659, 5, 'http://www.dr-chuck.com/dr-chuck/resume/index.htm')
4 行。
你可以随心所欲地运行 sprank.py,它每次运行时都会简单地优化 PageRank。你甚至可以运行几次 sprank.py,然后用 spider.py 爬取一些更多页面,然后再次运行 sprank.py 以重新收敛 PageRank 值。搜索引擎通常一直运行爬取和排名程序。
如果你想在不重新爬取网页的情况下重新启动 PageRank 计算,可以使用 spreset.py,然后重新启动 sprank.py。
多少次迭代:50
1 0.546848992536
2 0.226714939664
3 0.0659516187242
4 0.0244199333
5 0.0102096489546
6 0.00610244329379
...
42 0.000109076928206
43 9.91987599002e-05
44 9.02151706798e-05
45 8.20451504471e-05
46 7.46150183837e-05
47 6.7857770908e-05
48 6.17124694224e-05
49 5.61236959327e-05
50 5.10410499467e-05
[(512, 0.0296), (1, 12.79), (2, 28.93), (3, 6.808), (4, 13.46)]
对于 PageRank 算法的每次迭代,它都会打印每个页面的平均 PageRank 变化。网络最初非常不平衡,因此单个页面的 PageRank 值在迭代之间会剧烈变化。但在几次短暂的迭代中,PageRank 会收敛。你应该运行足够长时间的 sprank.py,直到 PageRank 值收敛。
如果你想可视化当前 PageRank 最高的页面,运行 spjson.py 读取数据库并将连接最紧密的页面的数据以 JSON 格式写入,以便在 Web 浏览器中查看。
正在 spider.json 上创建 JSON 输出...
多少个节点?30
在浏览器中打开 force.html 以查看可视化结果
你可以通过在 Web 浏览器中打开文件 force.html 来查看此数据。这显示了节点和链接的自动布局。你可以单击并拖动任何节点,也可以双击一个节点以查找该节点代表的 URL。
如果你重新运行其他实用程序,请重新运行 spjson.py 并在浏览器中按刷新以从 spider.json 获取新数据。
可视化邮件数据
到本书的这一点,你已经非常熟悉我们的 mbox-short.txt 和 mbox.txt 数据文件了。现在是时候将我们对电子邮件数据的分析提升到一个新的水平了。
在现实世界中,有时你必须从服务器下拉邮件数据。这可能需要相当长的时间,并且数据可能不一致、充满错误,需要大量清理或调整。在本节中,我们将使用迄今为止最复杂的应用程序,下拉近 1 GB 的数据并对其进行可视化。
 Sakai 开发者列表的词云
Sakai 开发者列表的词云
你可以从以下地址下载此应用程序:
https://www.py4e.com/code3/gmane.zip
我们将使用一个名为 gmane 的免费邮件列表归档服务的数据——该服务现已关闭,为了本课程的目的,一个部分存档保存在 http://mbox.dr-chuck.net。gmane 服务在开源项目中非常受欢迎,因为它为其电子邮件活动提供了一个很好的可搜索存档。
http://mbox.dr-chuck.net/export.php
当使用此软件爬取 Sakai 电子邮件数据时,它产生了近 1 GB 的数据,并且在几天内运行了多次。上述 ZIP 文件中的 README.txt 文件可能包含有关如何下载大部分 Sakai 电子邮件语料库的预爬取 content.sqlite 文件副本的说明,这样你就不必为了运行程序而爬取五天。如果你下载了预爬取的内容,你仍应运行爬取过程以赶上更新的消息。
第一步是爬取存储库。基本 URL 在 gmane.py 中是硬编码的,并且硬编码为 Sakai 开发者列表。你可以通过更改该基本 URL 来爬取另一个存储库。如果切换基本 URL,请确保删除 content.sqlite 文件。
gmane.py 文件作为一个负责任的缓存爬虫运行,它运行缓慢,每秒检索一封邮件消息,以避免被限流。它将其所有数据存储在数据库中,并且可以根据需要随时中断和重新启动。下拉所有数据可能需要很多小时。所以你可能需要重新启动几次。
下面是 gmane.py 检索 Sakai 开发者列表最后五条消息的运行示例:
多少条消息:10
http://mbox.dr-chuck.net/sakai.devel/51410/51411 9460
[email protected] 2013-04-05 re: [building ...\
http://mbox.dr-chuck.net/sakai.devel/51411/51412 3379\
[email protected] 2013-04-06 re: [building ...\
http://mbox.dr-chuck.net/sakai.devel/51412/51413 9903\
[email protected] 2013-04-05 [building sakai] melete 2.9 oracle ...\
http://mbox.dr-chuck.net/sakai.devel/51413/51414 349265\
[email protected] 2013-04-07 [building sakai] ...\
http://mbox.dr-chuck.net/sakai.devel/51414/51415 3481\
[email protected] 2013-04-07 re: ...\
http://mbox.dr-chuck.net/sakai.devel/51415/51416 0\
\
不以 From 开头
该程序从 1 开始扫描 content.sqlite,直到第一个尚未爬取的消息编号,并从该消息开始爬取。它继续爬取,直到爬取了所需数量的消息,或者到达一个看起来不是格式正确的 Mbox 消息的页面。
有时存储库会丢失一条消息。也许管理员可以删除消息,或者它们可能会丢失。如果你的爬虫停止了,并且看起来它遇到了丢失的消息,请进入 SQLite 管理器并添加一个包含丢失 ID 的行,将所有其他字段留空,然后重新启动 gmane.py。这将解除爬取过程的卡顿状态,并允许它继续。这些空消息将在过程的下一阶段被忽略。
一个好处是,一旦你爬取了所有消息并将它们保存在 content.sqlite 中,你可以再次运行 gmane.py 来获取发送到列表的新消息。
content.sqlite 数据非常原始,数据模型效率低下,并且未压缩。这是故意的,因为它允许你在 SQLite 管理器中查看 content.sqlite 以调试爬取过程中的问题。对此数据库运行任何查询都不是一个好主意,因为它们会相当慢。
第二个过程是运行程序 gmodel.py。这个程序从 content.sqlite 读取原始数据,并在文件 index.sqlite 中生成一个清理过且模型良好的数据版本。这个文件会比 content.sqlite 小得多(通常小 10 倍),因为它还压缩了头部和正文文本。
每次运行 gmodel.py 时,它都会删除并重建 index.sqlite,允许你调整其参数并编辑 content.sqlite 中的映射表以调整数据清理过程。这是 gmodel.py 的一个示例运行。它每处理 250 封邮件消息就打印一行,这样你可以看到一些进展,因为这个程序处理近 1 GB 的邮件数据可能需要运行一段时间。
加载了所有发件人 1588 和映射 28 dns 映射 1
1 2005-12-08T23:34:30-06:00 [email protected]
251 2005-12-22T10:03:20-08:00 [email protected]
501 2006-01-12T11:17:34-05:00 [email protected]
751 2006-01-24T11:13:28-08:00 [email protected]
...
gmodel.py 程序处理许多数据清理任务。
对于 .com、.org、.edu 和 .net,域名被截断为两级。其他域名被截断为三级。所以 si.umich.edu 变成 umich.edu,caret.cam.ac.uk 变成 cam.ac.uk。电子邮件地址也被强制转换为小写,并且一些像下面这样的 @gmane.org 地址
只要在消息语料库的其他地方存在匹配的真实电子邮件地址,就会被转换为真实地址。
在 mapping.sqlite 数据库中有两个表,允许你映射在邮件列表生命周期内发生变化的域名和单个电子邮件地址。例如,Steve Githens 在 Sakai 开发者列表的生命周期中随着工作变动使用了以下电子邮件地址:
我们可以在 mapping.sqlite 的 Mapping 表中添加两个条目,这样 gmodel.py 就会将所有三个地址映射到一个地址:
如果存在多个你想要映射到单个 DNS 的 DNS 名称,你也可以在 DNSMapping 表中进行类似的条目。以下映射已添加到 Sakai 数据中:
iupui.edu -> indiana.edu
因此,来自印第安纳大学各个校区的所有帐户都被一起跟踪。
你可以反复重新运行 gmodel.py,边查看数据边添加映射,使数据越来越干净。完成后,你将在 index.sqlite 中拥有一个索引良好的邮件版本。这是用于进行数据分析的文件。使用这个文件,数据分析将非常快速。
第一个,最简单的数据分析是确定“谁发送了最多的邮件?”和“哪个组织发送了最多的邮件?”。这使用 gbasic.py 完成:
要转储多少个?5
已加载消息= 51330 主题= 25033 发件人= 1584
前 5 名电子邮件列表参与者
[email protected] 2657
[email protected] 1742
[email protected] 1591
[email protected] 1304
[email protected] 1184
前 5 名电子邮件列表组织
gmail.com 7339
umich.edu 6243
uct.ac.za 2451
indiana.edu 2258
unicon.net 2055
请注意 gbasic.py 与 gmane.py 甚至 gmodel.py 相比运行速度快了多少。它们都在处理相同的数据,但 gbasic.py 使用的是 index.sqlite 中压缩和规范化的数据。如果你有大量数据要管理,像这个应用程序这样的多步骤过程可能需要稍长的时间来开发,但当你真正开始探索和可视化你的数据时,它会为你节省大量时间。
你可以使用文件 gword.py 生成主题行中词频的简单可视化:
计数范围:33229 129
输出已写入 gword.js
这将生成文件 gword.js,你可以使用 gword.htm 对其进行可视化,以生成类似于本节开头所示的词云。
第二个可视化由 gline.py 生成。它计算随时间变化的组织邮件参与情况。
已加载消息= 51330 发件人= 1584
前 10 名组织
['gmail.com', 'umich.edu', 'uct.ac.za', 'indiana.edu',
'unicon.net', 'tfd.co.uk', 'berkeley.edu', 'longsight.com',
'stanford.edu', 'ox.ac.uk']
输出已写入 gline.js
其输出被写入 gline.js,并使用 gline.htm 进行可视化。
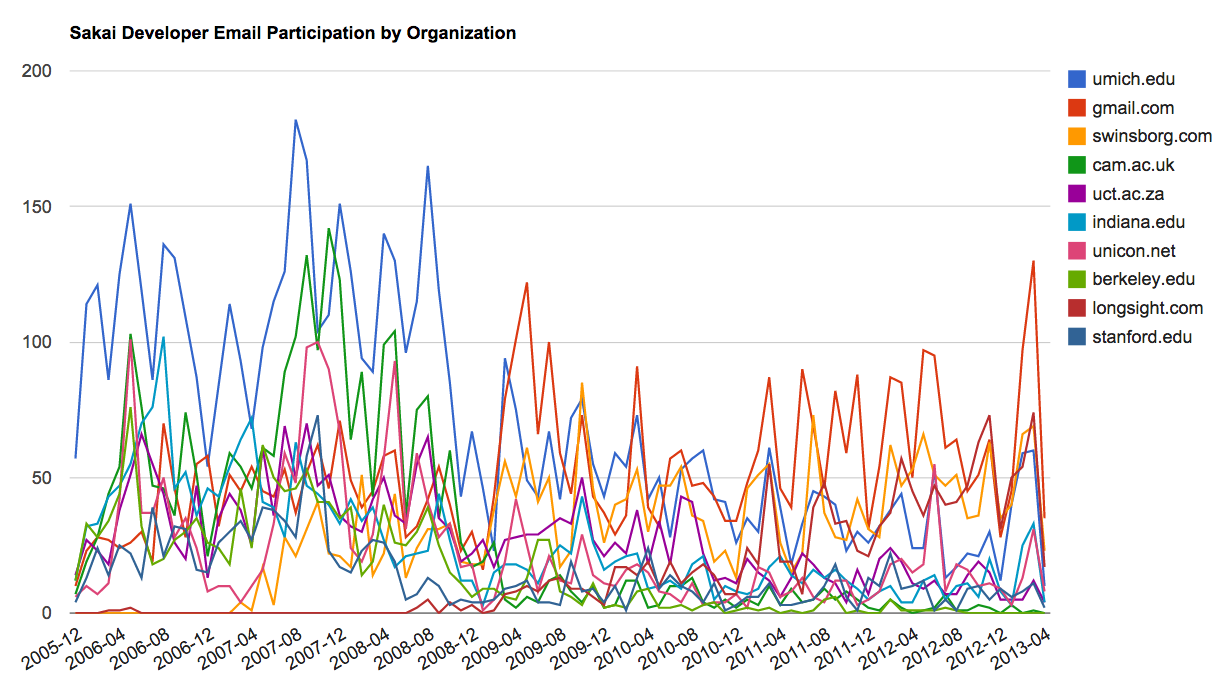 按组织划分的 Sakai 邮件活动
按组织划分的 Sakai 邮件活动
这是一个相对复杂和精密的应用程序,并具有进行一些真实数据检索、清理和可视化的功能。
如果你在本书中发现错误,欢迎使用 Github 给我发送修正。