Project 2A Ngordnet (NGrams)
常见问题解答
每个作业的顶部都会链接一个常见问题解答。您也可以通过在网址末尾添加“/faq”来访问。项目 2A 的常见问题解答位于此处。
介绍
在这个项目中,我们将构建一个基于浏览器的工具,用于探索英语文本中单词用法的历史。我们提供了前端代码(使用 Javascript 和 HTML),用于收集用户输入并显示输出。您的 Java 代码将作为此工具的后端,接收输入并生成相应的输出以供显示。
您可以在下方找到该项目的视频介绍(或者点击此链接观看)。
为了支持该工具,您需要编写一系列 Java 包来进行数据分析。在此过程中,您将获得大量使用各种实用数据结构的经验。项目初期 (proj2a) 会明确告知您需要编写哪些函数和创建哪些类。项目后期 (proj2b) 则会更加开放,允许您自由设计。
您可以在 ngordnet.datastructur.es 查看项目组提供的参考答案。
开始
首先,请像往常一样使用 git pull skeleton main 命令。
您还需要下载 Project 2 的数据文件(由于文件体积较大,GitHub 上未提供这些数据)。
下载数据文件在此链接。
您需要将下载的数据解压到 proj2 目录下,确保
data文件夹与src和static文件夹同级。
完成以上步骤后,您的 proj2a 目录结构应该如下所示:
proj2a
├── data
│ ├── ngrams
│ └── wordnet
├── src
├── static
├── tests
请注意,我们在初始代码中已经设置了隐藏的 .gitignore 文件,这样 Git 就不会上传这些数据文件了。这是为了避免不必要的问题。
将数据文件上传到 GitHub 会导致很多问题,请勿修改任何名为 .gitignore 的文件。如果您需要在多台机器上进行开发,请在每台机器上分别下载 zip 文件。
如果 NgordnetQuery 编译失败,请确保您正在使用 Java 15 或更高版本 (推荐 17+)。
您可以点击此链接观看视频,了解如何配置环境以进行项目开发。需要注意的是,视频中名为 hugbrowsermagic 的目录,在您拿到的初始代码中已经被更名为 browser。
构建 NGrams 查看器
Google Ngram 数据集 提供了关于英文文本中所有被观察到的词汇和短语的历史频率的大量信息(数TB级别)(或者更准确地说,是所有被观察到的 ngrams)。 Google 提供了 Google Ngram Viewer 在线工具,使用户能够可视化词语和短语在历史上的相对流行程度。 例如,上述链接展示了“global warming”(一个2-gram)和“to the moon”(一个3-gram)这两个短语的加权历史流行度。
在Project 2A中,你将构建一个工具,该版本仅处理1-gram。 换句话说,你只能处理单个词。 我们将只使用完整1-gram数据集的一个小部分(大约300MB)。更大的数据集需要更复杂的技术,这超出了本课程的范围。
TimeSeries
TimeSeries 是现有 TreeMap 类的一个特殊用途的扩展,其中键类型参数始终为 Integer,值类型参数始终为 Double。 每个键对应一个年份,而每个值则对应于该年份的数值数据点。 您可以从此处找到 TreeMap API,以查看哪些方法可供您使用。
例如,以下代码将创建一个 TimeSeries,并将 1992 年与值 3.6 相关联,将 1993 年与 9.2 相关联。
TimeSeries ts = new TimeSeries();
ts.put(1992,3.6);
ts.put(1993,9.2);
TimeSeries 类提供了一些 TreeMap 类(它扩展了该类)的附加实用程序方法。
task
根据文件中提供的 API,填写
TimeSeries类(位于src/ngrams/TimeSeries.java文件中)。 请务必阅读每种方法上方的注释。
有关如何使用
TimeSeries对象的示例,请查看我们提供的TimeSeriesTest.java文件中名为testFromSpec()的测试。 此测试创建猫和狗数量的TimeSeries,然后计算它们的总和。 请注意,1993 年没有值,因为该年份未出现在任何一个TimeSeries中。
不允许向该类添加额外的公共方法,但欢迎添加私有方法。
TimeSeries 提示
TimeSeries对象不应具有实例变量。TimeSeries是TreeMap。 这意味着您的TimeSeries类也可以访问 TreeMap 具有的所有方法; 请参阅 TreeMap API。- 有若干方法需要你比较两个
TimeSeries的数据。 如果某年份或数值不可用,不应使用任何代码来填充零。 - 提供的
TimeSeriesTest类提供了TimeSeries类的简单测试。 欢迎添加你自己的测试。- 请注意,我们给您的单元测试不评估
dividedBy方法的正确性。
- 请注意,我们给您的单元测试不评估
- 这是因为双精度数容易产生舍入误差,尤其是在进行除法运算后(具体原因将在61C课程中学习)。因此,当
x和y均为双精度数时,assertThat(x).isEqualTo(y)可能会意外返回false。相反,你应该使用assertThat(x).isWithin(1E-10).of(y),只要x和y之间的差值在范围内,该方法就会返回true。 - 您可以假设
dividedBy运算永远不会除以零。
NGramMap
NGramMap 类将提供各种便捷的方法来与 Google 的 NGrams 数据集进行交互。这项任务比创建 TimeSeries 类更具开放性和挑战性。和 TimeSeries 类一样,你需要完善 NGramMap.java 文件中已有的方法。NGramMap 不应扩展任何类。
如果调用返回 TimeSeries 类型的方法,但没有对应的数据,则应该返回一个空的 TimeSeries 实例。例如,ngm.weightHistory("asdfasdf") 应该返回一个空的 TimeSeries 实例,因为 "asdfasdf" 不是数据集中的单词。举例来说,如果 adopt 这个词在 1400 年到 1410 年间没有任何数据,那么 ngm.countHistory("adopt", 1400, 1410) 也应该返回一个空的 TimeSeries 实例。
task
请根据文件中提供的 API 填写
NGramMap类(位于src/ngrams/NGramMap.java文件中)。再次,请务必阅读每个方法上方的注释。
有关
NGramMap工作原理的示例,NGramMapTest中的testOnLargeFile()会从top_14377_words.csv和total_counts.csv文件(如下所述)创建一个NGramMap。然后,它执行与 1850 年至 1933 年间单词“fish”和“dog”的出现次数相关的各种操作。
您不得向此类添加其他公共方法。欢迎您添加其他私有方法。
输入文件格式
NGram 数据集有两种不同的文件类型。第一种类型是“words file”(单词文件)。单词文件中的每一行都提供有关特定单词在给定年份的英语历史记录的制表符分隔信息。
airport 2007 175702 32788
airport 2008 173294 31271
request 2005 646179 81592
request 2006 677820 86967
request 2007 697645 92342
request 2008 795265 125775
wandered 2005 83769 32682
wandered 2006 87688 34647
wandered 2007 108634 40101
wandered 2008 171015 64395
每行中的第一个条目是单词。第二个条目是年份。第三个条目是该单词当年在任何书中出现的次数。第四个条目是包含该单词的不同来源的数量。您的程序应忽略第四列。 例如,从上面的文本文件中,我们可以观察到单词“wandered”在 2008 年出现了 171,015 次,并且这些词语出现在 64,395 个不同的来源中。对于本项目,我们从不关心第四个条目(总卷数)。
另一种类型的文件是“counts file”(计数文件)。计数文件中的每一行都提供有关每个日历年可用数据总语料库的逗号分隔信息。
1470,984,10,1
1472,117652,902,2
1475,328918,1162,1
1476,20502,186,2
1477,376341,2479,2
每行中的第一个条目是年份。第二个是该年从所有文本中记录的单词总数。第三个数字是该年的文本总页数。第四个是该年的不同来源总数。您的程序应忽略第三列和第四列。例如,我们看到 Google 恰好有 1470 年的一个英语文本,其中包含 984 个单词和 10 页。对于我们项目的目的,10 和 1 是无关紧要的。
你可能想知道为什么一个文件使用制表符分隔,而另一个文件使用逗号分隔。我没有这样做,是 Google 做的。幸运的是,处理这种差异并不困难。
NGramMap 提示
对于这个项目,有很多需要考虑的地方。我们试图模拟真实场景,即你遇到一个大型开放式问题,需要从零开始寻找解决方案。这可能会让人望而却步!可能需要花费一些时间和进行大量实验才能找到方法。为了降低难度,我们至少提供了一份需要实现的函数列表。请记住,在实际应用中(以及在proj2b和proj3中),甚至函数列表也需要你自己决定。
你的代码应该足够高效,能够使用top_14377_words.csv创建NGramMap。加载时间应少于60秒(在较旧的计算机上可能稍长)。如果你的计算机有足够的内存,你也应该能够加载top_49887_words.csv。
- 在这个类中,你大部分的工作是实现构造器。你需要解析所提供的数据文件,并将数据存储在你选择的数据结构里。
- 这个选择至关重要,因为选择合适的数据结构能让你在实现其他方法时事半功倍。因此,我们建议你先浏览一下其他方法,以便确定最适合的数据结构,然后再开始实现构造器。
- 避免将HashMap或TreeMap用作map的[实际类型参数]。这通常意味着你需要自定义类型。也就是说,如果你的实例变量包含类似
HashMap<blah, HashMap<blah, blah>>的嵌套映射,那么TimeSeries或者你设计的其他类可能会更有用。 - 我们没有讲解如何在Java中读取文件。我们建议使用
In类。可以在此处找到官方文档。当然,你也可以使用你在网上学习到的任何技术。我们提供了一个示例类FileReaderDemo.java,其中提供了如何使用In的示例。 - 如果使用
In类,请避免使用readAllLines或readAllStrings方法。这些方法很慢。而是每次读取一部分输入数据。有关示例,请参见src/main/FileReaderDemo.java。- 另外,要检查文件是否还有剩余行,应该使用
hasNextLine方法(而不是isEmpty)。
- 另外,要检查文件是否还有剩余行,应该使用
- 我们提供的测试只覆盖了部分方法,而且有些方法只在大文件上进行测试。你需要编写其他测试。
- 建议你从较小的输入文件(例如
very_short.csv或words_that_start_with_q.csv)开始,而不是直接使用大型输入文件(如top_14377_words.csv)。
- 建议你从较小的输入文件(例如
- 和TimeSeries一样,如果数据不可用,你不应该编写任何填充零值的代码。
- 为了提高代码效率,你可以假设年份参数的取值范围在1400到2100之间。这些变量作为常量
MIN_YEAR和MAX_YEAR存储在TimeSeries类中。 NGramMap不应扩展任何其他类。- 你的方法实现应该尽可能简洁!如果选择了合适的数据结构,这些方法的代码量应该不会很大。
- 如果单词不合法,则返回一个空的
TimeSeries。
HistoryTextHandler
在Project 2A的最后一部分中,我们将进行一些软件工程,以设置一个可以处理NgordnetQueries的Web服务器。虽然此内容与数据结构没有严格的关系,但是能够采用项目并将其部署以供实际使用非常重要。
注意: 只有当你确信TimeSeries和NGramMap能够正常工作后,再开始这部分内容。
请在你的网页浏览器中打开
static文件夹下的ngordnet_2a.html文件。你可以通过操作系统的 Finder 菜单打开它,或者在 IntelliJ 中右键点击ngordnet_2a.html文件,选择 "Open in",再选择 "Browser" 打开。你可以使用任何你喜欢的浏览器,不过助教们最熟悉 Chrome。你将会看到一个基于网页浏览器的界面,最终(当你完成项目时)允许用户输入一个单词列表并显示可视化结果。尝试在 "words" 框中输入 "cat, dog",然后点击
History (Text)。你会发现没有任何实际的信息显示出来。可选:如果你打开网页浏览器中的开发者工具(可以在 Google 上搜索一下操作方法),你将会看到一个类似 "CONNECTION_REFUSED" 或 "INVALID_URL" 的错误。问题在于 Javascript 尝试访问服务器来生成结果。但当前没有正在运行的 Web 服务器能够处理查看 cat 和 dog 历史记录的请求。打开
main.Main类。这个类的 API 如下所示:首先,我们在NgordnetServer对象上调用startUp,然后我们使用register命令来注册一个或多个NgordnetQueryHandler。这里的具体细节超出了本课程的范围。基本的想法是,当你调用
hns.register("historytext", new DummyHistoryTextHandler(ngm))时,会创建一个DummyHistoryTextHandler类型的对象,该对象将处理对History (Text)按钮的任何点击。尝试运行
main.Main类。在 IntelliJ 的终端输出中,你应该看到如下一行:INFO org.eclipse.jetty.server.Server - Started...,这意味着服务器已正确启动。现在再次打开ngordnet_2a.html文件,再次输入 "cat, dog",然后点击History (Text)。这一次,你应该看到一条消息,内容如下:You entered the following info into the browser:
Words: [cat, dog]
Start Year: 2000
End Year: 2020现在打开
main.DummyHistoryTextHandler,你将会看到一个handle方法。此方法会在用户每次点击History (Text)按钮时被调用。正确的行为是,当用户点击上述History (Text)按钮时,应该显示以下文本:
cat: {2000=1.71568475416827E-5, 2001=1.6120939684412677E-5, 2002=1.61742010630623E-5, 2003=1.703155141714967E-5, 2004=1.7418408946715716E-5, 2005=1.8042211615010028E-5, 2006=1.8126126955841936E-5, 2007=1.9411504094739293E-5, 2008=1.9999492186117545E-5, 2009=2.1599428349729816E-5, 2010=2.1712564894218663E-5, 2011=2.4857238078766228E-5, 2012=2.4198586699546612E-5, 2013=2.3131865569578688E-5, 2014=2.5344693375481996E-5, 2015=2.5237182007765998E-5, 2016=2.3157514119191215E-5, 2017=2.482102172595473E-5, 2018=2.3556758130732888E-5, 2019=2.4581322086049953E-5}
dog: {2000=3.127517699525712E-5, 2001=2.99511426723737E-5, 2002=3.0283458650225453E-5, 2003=3.1470761877596034E-5, 2004=3.2890514515432536E-5, 2005=3.753038415155302E-5, 2006=3.74430614362125E-5, 2007=3.987077208249744E-5, 2008=4.267197824115907E-5, 2009=4.81026086549733E-5, 2010=5.30567576173992E-5, 2011=6.048536820577008E-5, 2012=5.179787485962082E-5, 2013=5.0225599367200654E-5, 2014=5.5575537540090384E-5, 2015=5.44261096781696E-5, 2016=4.805214145459557E-5, 2017=5.4171157785607686E-5, 2018=5.206751570646653E-5, 2019=5.5807040409297486E-5}
为了通过自动评分,输出格式必须完全一致。
- 所有文本行,包括最后一行,都应该以换行符结尾。
- 所有空格和标点符号(逗号、大括号、冒号)都应与上述示例一致。
这些数字表示给定年份中 cat 和 dog 这两个词的加权流行度历史记录 (即,根据词频计算出的流行程度)。由于四舍五入误差,您的数字可能与上面显示的数字不完全相同。您的格式应与上面显示的完全相同:具体来说,是单词,后跟一个冒号,后跟一个空格,后跟相应 TimeSeries 的字符串表示形式,其中键值对以逗号分隔的列表形式给出,并用大括号括起来,键和值之间用等号分隔。请注意,您无需编写任何代码来生成每个 TimeSeries 的字符串表示形式,只需使用 toString() 方法即可。
现在是时候实现 HistoryText 按钮了!
task
创建一个名为
HistoryTextHandler.java的新文件,该文件接受给定的NgordnetQuery并返回与上述格式相同的字符串。然后,修改
Main.java,以便在有人单击“History (Text)”时使用您编写的HistoryTextHandler。换句话说,应该注册您编写的HistoryTextHandler类,而不是注册DummyHistoryTextHandler。
您可能会注意到,当服务器启动时,
Main.java会打印出一个链接。 如果觉得这样更方便,可以直接点击链接,而无需手动打开ngordnet_2a.html文件。
HistoryTextHandler 提示
``- HistoryTextHandler 的构造函数应采用以下形式:public HistoryTextHandler(NGramMap map)`。
- 参考
DummyHistoryTextHandler.java的代码,适当地模仿其模式。能够修改示例代码并应用到实际需求中是非常重要的技能。大胆尝试,即使出错也没关系! - 对于 Project 2A,您可以忽略
NgordnetQuery的k实例变量。 - 使用从
TreeMap继承的TimeSeries类中内置的.toString()方法。 - 为了使您的
HistoryTextHandler能够执行有用的操作,它需要能够访问存储在您的NGramMap中的数据。请勿将 NGRAM MAP 设置为静态变量!这被称为“全局变量”,通常不是解决问题的最佳方案。提示:您的HistoryTextHandler类可以有一个构造函数。 - 如果单词无效,请参考
NGramMap中处理无效单词的方式。
HistoryHandler
上一节中基于文本的历史记录,其作用主要在于自动评分,除此之外用途不多。要真正利用我们的工具发现有趣的信息,需要借助可视化。
main.PlotDemo 提供了示例代码,该代码使用您的 NGramMap 生成一个可视化图,显示 1900 年至 1950 年间 cat 和 dog 这两个词的加权流行度历史记录。尝试运行它。如果您的 NGramMap 类正确,您应该在控制台中看到一个很长的字符串,可能如下所示:
iVBORw0KGg...
此字符串是图像文件的 base 64 编码。要对其进行可视化,请转到 codebeautify.org。将整个字符串复制并粘贴到网站中,您应该会看到一个类似于下图的图:
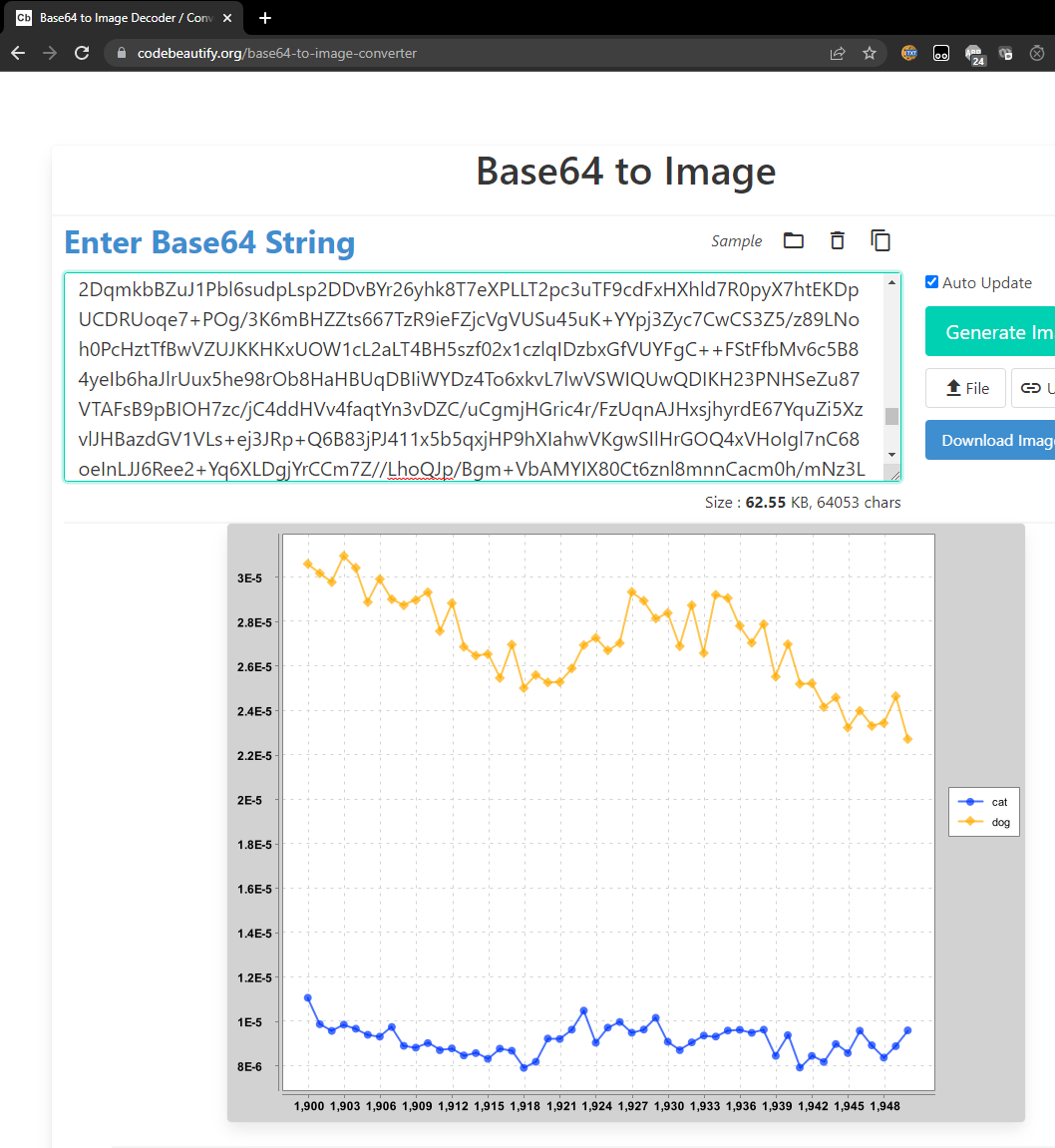
这里发生了什么?您的代码打印的字符串就是图像。请记住,任何数据都可以表示为一串位。该网站知道如何使用预定义的标准将此字符串解码为相应的图像。
如果您查看绘图库,此代码依赖于 ngordnet.Plotter.generateTimeSeriesChart 方法,该方法接受两个参数。第一个是字符串列表,第二个是 List<TimeSeries>。TimeSeries 都以不同的颜色绘制,并且每个都分配了字符串列表中给出的标签。两个列表的长度必须相同(因为第 i 个字符串是第 i 个时间序列的标签)。
ngordnet.Plotter.generateTimeSeriesChart 方法返回一个 XYChart 类型的对象。然后,可以使用 ngordnet.Plotter.encodeChartAsString 方法将此对象转换为 base 64,也可以使用 ngordnet.Plotter.displayChart 直接将其显示在屏幕上。
在 Web 浏览器中,重新打开 static 文件夹下的 ngordnet_2a.html 文件。确保 main.Main 类正在运行,然后在 "words" 框中输入 "cat, dog",并点击 "history" 按钮。您将看到如下所示的图像:
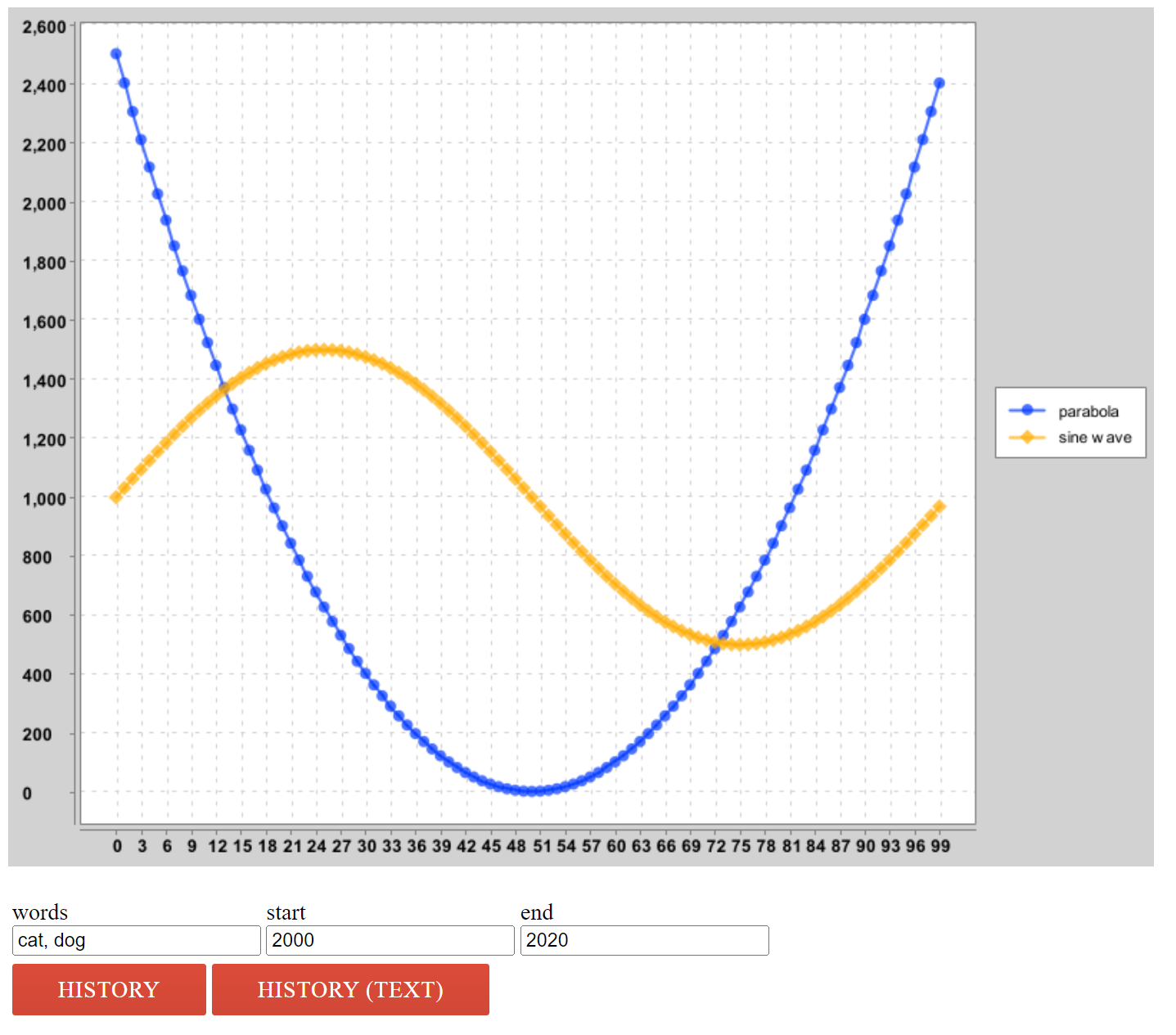
您会注意到,该代码没有绘制 cat 和 dog 的历史记录,而是绘制了抛物线和正弦曲线。如果您打开 DummyHistoryHandler,您就会明白为什么。
task
创建一个名为
HistoryHandler.java的新文件,该文件接受给定的NgordnetQuery并返回一个字符串,其中包含相应图的 base-64 编码图像。然后,修改
Main.java,以便在有人单击“History”按钮时调用您的HistoryHandler。
HistoryHandler 提示
HistoryHandler的构造函数应采用以下形式:public HistoryHandler(NGramMap map)。- 就像之前一样,使用
DummyHistoryHandler.java作为指南。正如上一节中提到的,我们真的希望您学习修改复杂的库代码以获得您想要的行为的技能。
Deliverables and Scoring
您负责实现四个类:
- TimeSeries (30%): 正确地实现
TimeSeries.java。 - NGramMap Count (20%): 正确地实现
NGramMap.java中的countHistory()和totalCountHistory()方法。 - NGramMap Weight (30%): 正确地实现
NGramMap.java中的weightHistory()和summedWeightHistory()方法。 - HistoryTextHandler (10%): 正确地实现
HistoryTextHandler.java。 - HistoryHandler (10%): 正确地实现
HistoryHandler.java。
提交
要提交项目,请添加并提交文件,然后推送到您的远程仓库。然后,前往 Gradescope 上的相关作业页面并提交。
此作业的自动评分器采用以下速率限制方案:
- 从项目发布之日起到截止日期,您将拥有 8 个配额;每个配额每 24 小时刷新一次。
致谢
本作业的 WordNet 部分改编自 Alina Ene 和 Kevin Wayne 在普林斯顿大学开设的 Wordnet 作业。