Project 2B Ngordnet (Wordnet)
常见问题解答
每个作业都会在顶部链接一个常见问题解答。您也可以通过在 URL 末尾添加“/faq”来访问它。项目 2B 的常见问题解答位于此处。
检查点和设计文档截止日期:2024年3月15日
编码截止日期:2024年4月1日
在这个项目中,您将完成 NGordnet 工具的实现。
由于项目较新,规范中可能存在疏漏或令人困惑之处。如果遇到任何问题,请在Ed上提问。
重要提示: 在您阅读 2B 规范后,您可能会想开始编码。不要这样做!
在开始编写2B的任何代码之前,请务必阅读2C规范,因为2C的内容可能会影响你的设计。您可以在此处找到它。
然后,在开始编码之前,完成 Project 2B/C: Checkpoint 和 Design Document。
设计说明
在设计项目时,请务必提前考虑所有需求。充分的计划可以避免在后续阶段重写大量代码。
如果发现存在大量重复代码,可以考虑直接重用或稍作修改,避免重复劳动。
项目设置
本项目的配置方式与其他实验或项目有所不同,请务必仔细阅读本节内容!
骨架设置
- 和本课程的其他作业一样,运行
git pull skeleton main命令来获取项目的初始代码。 - 使用此链接下载此项目的
data文件,并将它们移动到与src同一级别的proj2b文件夹中。
配置完成后,你的 proj2b 目录结构应该如下所示:
proj2b
├── data
│ ├── ngrams
│ └── wordnet
├── src
├── static
├── tests
开始
重要提示: 强烈建议在开始编写代码甚至设计项目之前,先完成 Project 2B/C: Checkpoint。这有助于你更好地理解项目。同时,你需要向Gradescope提交一份设计文档。关于设计文档的更多细节,请参考交付内容和评分部分。
task
完成 Project 2B/C: Checkpoint
完成检查点后,完成 设计文档
本项目的重点在于让你能够设计出高效且正确的实现方案。良好的设计对于应对各种情况至关重要。在编写设计文档之前,请务必仔细阅读2B和2C的规范。 课程组制作了一些关于本项目和入门代码的介绍视频,请点击here观看。请注意,项目结构有所调整,部分信息可能已过期,请注意甄别!
我们还创建了两个非常有用的工具,强烈建议大家使用!它们可以帮助你探索数据集,了解参考答案在不同输入下的表现,并生成单元测试所需的预期输出(详见测试你的代码)。这些工具的链接会出现在本文档的相应位置。
- Wordnet 可视化工具: 可用于直观地了解同义词集和下位词的工作方式,并测试不同单词/单词列表的潜在测试用例输入。点击“?”气泡可以查看工具的各项功能说明!
- 参考答案网页: 可用于生成不同测试用例输入的预期输出。使用它来编写你的单元测试!
task
通读整个 2B/C 规范并完成 Project 2B/C: Checkpoint
完成设计文档
使用 WordNet 数据集
在将 WordNet 纳入我们的项目之前,我们首先需要了解 WordNet 数据集。
WordNet 是“英语的语义词典”,被计算语言学家和认知科学家广泛使用;例如,它是 IBM Watson 的一个关键组成部分。 WordNet 将单词分组为称为同义词集的同义词集合,并描述它们之间的语义关系。其中一种关系是 is-a 关系,它将下位词 (hyponym,即更具体的概念) 连接到上位词 (hypernym,即更一般的概念)。例如,“change”是“demotion”的上位词,因为“demotion”是(一种)“change”。 “change”反过来又是“action”的下位词,因为“change”是(一种)“action”。下面给出了英语中一些下位词关系的视觉描述:

上图中的每个节点代表一个同义词集。同义词集由一组意思相同的英语单词组成,可能包含一个或多个单词。例如,"jump, parachuting" 这样一个同义词集,表示的是使用降落伞降落的行为。“jump, parachuting”是“descent”的下位词,因为前者是后者的一种。 英语单词可能属于多个词集,这意味着一个单词可能有多种含义。例如,"jump" 这个词也属于词集 "jump, leap",它代表了 'jump' 这个词更偏向比喻的含义 (比如出席人数的激增),而非字面意义上从一个词集跳到另一个词集 (比如跳过水坑)。'jump, leap' 词集的上位词是 'increase',因为 'jump, leap' 是 'increase' 的一种。当然,还有其他方式可以 'increase',比如通过 'augmentation'。因此,图中 'increase' 指向 'augmentation' 的箭头也就不足为奇了。
词集可能不仅包括单词,还包括所谓的词语搭配(collocations)。可以将它们理解为经常一起出现的词语组合,以至于被视为一个整体,例如鼻塞剂。为了避免歧义,在本文档中,我们将用下划线 _ 分隔搭配的组成词,而不是英语中通常用空格分隔的约定。为简单起见,我们将在本文档中将搭配简称为“单词”。
一个词集可能同时是多个词集的下位词。例如,'actifed' 既是 'antihistamine' (抗组胺药) 的下位词,也是 'nasal_decongestant' (鼻塞剂) 的下位词,因为它同时属于这两类。
如果您好奇,可以通过使用 Web 界面浏览 Wordnet 数据库,但本项目中无需用到。
下位词(基本情况)
设置 HyponymsHandler
在您的浏览器中打开
static文件夹下的ngordnet.html文件。如果忘记了具体步骤,可以参考这里的第一条说明。您会看到一个新的按钮:“Hyponyms”。请注意,还有一个名为k的新输入框。尝试单击 Hyponyms 按钮。如果点击后没有反应,可以打开浏览器的开发者工具查看错误信息。
在 Project 2B 中,您的主要任务是实现此按钮,这将需要读取不同类型的数据集并将结果与 Project 2A 中的数据集进行综合。与 2A 不同,你需要自己设计所需的类来完成这个任务。
- 修改
HyponymsHandler文件,使其在用户点击浏览器中的 Hyponyms 按钮后,简单地返回单词 "Hello!"。应使HyponymsHandler类继承NgordnetQueryHandler类。可参考其他的 Handler 类示例。注册 handler 时,请务必使用字符串 "hyponyms" 作为register方法的第一个参数,切勿使用 "hyponym"。 - 首先打开你的
ngordnet.main.Main.java文件。 - 修改
Main文件,完成新 handler 的注册,使其能够处理 hyponyms 请求后,启动Main并在你的 web 浏览器中再次尝试点击 Hyponyms 按钮。你应该看到文本 "Hello"。
如果你看到类似 "Could not load file some_file_here.txt" 的错误,则可能表明你的项目没有正确设置。请确保你拥有与 项目设置 部分中声明的相同的目录结构。
下位词处理器(基本情况)
接下来,您将实现 Hyponyms 按钮的部分功能。目前,此按钮应:
- 假定输入的“words”仅包含一个单词。
- 忽略 startYear、endYear 和 k。
- 返回包含该单词及其所有下位词的列表的字符串,列表需务必按照字母顺序排列,且不包含重复单词。
例如,假设 WordNet 数据集如下图所示(作为输入文件 synsets11.txt 和 hyponyms11.txt 提供给你)。假设用户输入“descent”并单击 Hyponyms 按钮。
在这种情况下,你的处理程序的输出应为一个字符串,该字符串表示包含“descent”、“jump”和“parachuting”的列表,即 [descent, jump, parachuting]。这些单词已按字母顺序排列。
作为另一个例子,假设我们使用更大的数据集,例如如下面的数据集所示(作为输入文件 synsets16.txt 和 hyponyms16.txt 提供给你):
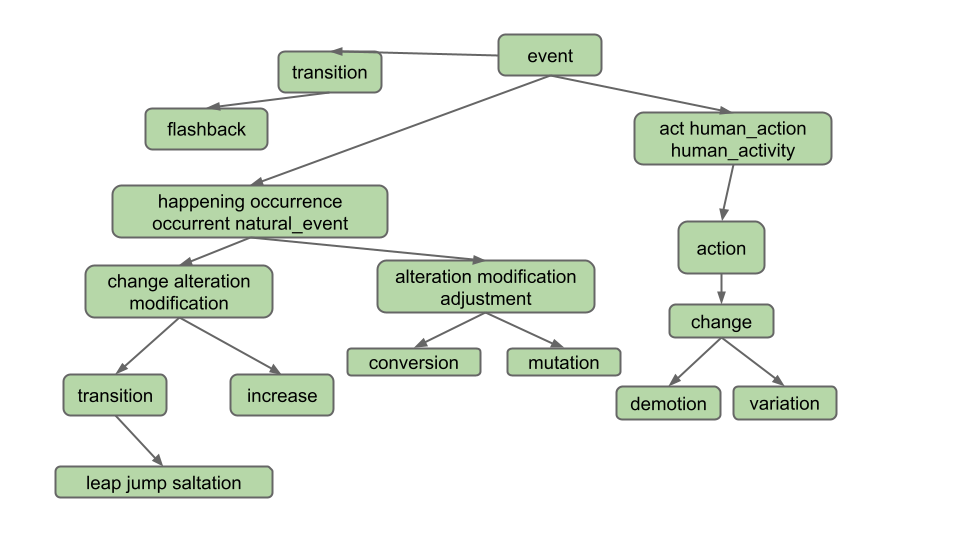
假设用户输入“change”并单击 Hyponyms 按钮。在这种情况下,下位词是蓝色节点所代表的所有单词:
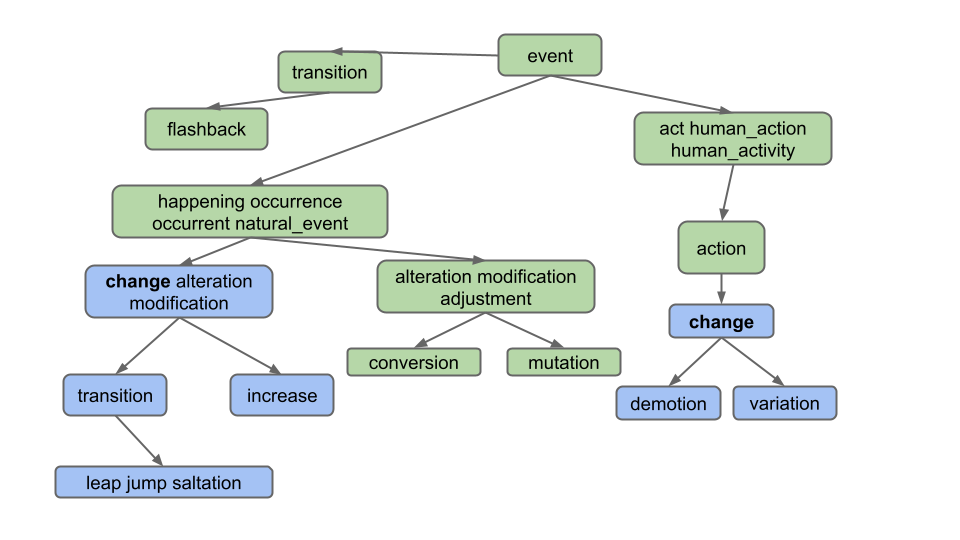
也就是说,最终输出为 [alteration, change, demotion, increase, jump, leap, modification, saltation, transition, variation]。请注意,即使“change”属于两个不同的同义词集,它也只出现一次。
注意:请勿过度解读。请注意输出不包括:
- 同义词的同义词(例如,不包括
"adjustment") - 同义词的下位词(例如,不包括
"conversion") - 下位词的其他定义的下位词(例如,不包括
"flashback",它是"transition"的另一个定义的下位词)
task
实现
HyponymsHandler.java和任何辅助类。注意: 请阅读下面的提示,因为你不应该在此类中编写所有代码。
要完成此任务,您需要确定需要创建哪些类来支持
HyponymsHandler。请勿将所有代码都写在 HYPONYMS HANDLER 中。相反,你应该有辅助类。例如,在 2A 中,为了处理“History”按钮,我们创建了一个NGramMap类。你需要在 2B 中做类似的事情,使用你自己的类。你还需要了解 WordNet 数据集的输入格式。此描述在下面的部分中给出。
在这部分,禁止在代码中导入任何现成的图库。例如,您不能导入普林斯顿算法教科书(可选)中提供的图的实现。您需要自行构建图类。
提示
- 就像2A中的NGramMap一样,建议您的辅助类只在构造函数中解析输入文件一次。切勿创建每次调用都需要读取整个输入文件的方法! 这样做效率会非常低。
- 我们强烈建议为此项目创建至少两个类,具体如下:一个类用于实现有向图。另一个类用于读取WordNet数据集,并创建有向图类的实例。这个类还应该能够接收一个单词,并返回其下位词。您也可以选择创建额外的辅助类来处理遍历,但这不是强制性的——您也可以直接在图类中实现遍历。
- 暂时无需关注Truth测试的编写,我们将在后面的文档中详细说明。现在,您可以先使用Web前端,通过
synsets16.txt和hyponyms16.txt这两个文件中的示例输入(“descent”和“change”)进行验证。 - 尽管您可以(并且应该)为项目中创建的辅助类/方法编写单元测试,但另一种测试和观察代码运行情况的有效方法是:直接运行
Main.java,打开ngordnet.html,在输入框中填入数据,然后点击“Hyponyms”按钮。您可能会发现,通过这种可视化调试方式,能更好地理解项目。
WordNet 文件格式
现在我们描述存储 WordNet 数据集的两种类型的数据文件。这些文件采用逗号分隔格式,这意味着每行包含一个由逗号分隔的字段序列。
文件类型 #1:名词同义词集列表。
synsets.txt文件(以及文件名中包含synset的其他较小文件)列出了WordNet中的所有同义词集。每行数据的第一个字段是同义词集ID(整数类型),第二个字段是同义词集(synset),第三个字段是该同义词集的字典定义。例如,以下这行数据:6829,Goofy,a cartoon character created by Walt Disney这表示同义词集
{ Goofy }的ID为6829,其定义是“a cartoon character created by Walt Disney”。构成同义词集的各个名词之间用空格分隔(同义词集元素本身不允许包含空格)。同义词集ID的编号从0到S-1,这些ID会连续出现在synset文件中。这些ID非常有用,因为它们也会出现在下位词文件中,也就是文件类型#2中描述的文件。文件类型 #2:下位词列表。
hyponyms.txt文件(以及文件名中包含hyponym的其他较小文件)记录了下位词关系:每行数据的第一个字段是同义词集ID,后面的字段则是该同义词集直接下位词的ID。例如,以下这行数据:79537,38611,9007这表示同义词集79537(“viceroy vicereine”)有两个直接下位词,分别是38611(“exarch”)和9007(“Khedive”),说明exarch和Khedive都是viceroy(或vicereine)的一种。这些同义词集的信息可以从
synsets.txt文件中找到:79537,viceroy vicereine,governor of a country or province who rules...
38611,exarch,a viceroy who governed a large province in the Roman Empire
9007,Khedive,one of the Turkish viceroys who ruled Egypt between...可能会出现多行数据以相同的同义词集ID开头的情况。例如,在
hyponyms16.txt文件中,有:11,12
11,13
这表明,synset 12和13都是synset 11的直接下位词。这两种synset也可以合并在同一行,即下面的写法具有完全相同的含义:synset 12和13是synset 11的直接下位词。
11,12,13
你可能会问,为什么会有两种方式来表达同一件事?这是因为真实世界的数据往往是复杂的,我们需要处理这些复杂性。
推荐步骤
要使“下位词”按钮正常工作,你需要:
- 开发一个图。 如果你不熟悉这种数据结构,请查看第 21 和 22 讲。你应该使用不依赖于给定数据文件的操作来进行测试。 例如,我们的测试评估了
createNode和addEdge函数。我们通过图类的getNodes和neighbors函数来验证它们是否生成了正确的图。 你可以参考第22讲和23讲的内容,链接如下:第 22 讲和23。 - 编写代码,将WordNet数据集文件转化成图。 这可以是你的图的一部分,也可以是使用你的图的类。
- 编写代码,该代码接受一个单词,并使用图遍历来查找给定图中该单词的所有下位词。
我们强烈建议编写测试来评估上述示例的查询(例如,你可以查看 synsets11/hypernyms11 中“descent”的下位词,或 synsets16/hypernyms16 中“change”的下位词)。
测试应该在与其评估目标相适应的抽象层级编写。 例如,我们有一个名为 TestGraph 的类,用于评估我们的 Graph 类的各个方面。
或者作为另一个例子,我们的代码有一个名为 TestWordNet 的类,其中包含以下函数。
@Test
public void testHyponymsSimple(){
WordNet wn=new WordNet("./data/wordnet/synsets11.txt","./data/wordnet/hyponyms11.txt");
assertThat(wn.hyponyms("antihistamine")).isEqualTo(Set.of("antihistamine","actifed"));
}
请注意,你的WordNet类可能和我们的类有不同的功能,因此示例测试可能无法直接应用到你的代码中。 请注意,我们的测试在任何地方都没有使用 NGramMap,也没有使用 HyponymsHandler,也没有直接调用 Graph 类型的对象。 它是专门为测试WordNet类而设计的。 仅仅依赖浏览器测试会非常低效且令人沮丧!你应该利用JUnit的技能,对你构建的基础模块(例如Graph, WordNet等)进行充分的测试,建立信心。
设计提示
这个项目涉及进行各种不同的查找、图操作和数据处理操作。 没有一种正确的方法可以做到这一点。
你可能需要执行的一些示例查找:
- 给定一个词(例如“change”),哪些节点包含了这个词?
- 例如,在synsets16.txt中,change出现在synset 2和8中
- 给定一个整数索引,它对应哪个节点?
- 这是处理hyponyms.txt文件所必需的。 例如,在hyponyms16.txt中,我们知道synset 8的节点指向synset 9和10,所以我们需要能够找到synset 8对应的节点,从而获取它的邻居节点。
- 给定一个节点,这个节点包含哪些词?
- 例如,在synsets16.txt中,synset 11 包含 alteration、modification 和 adjustment 这几个词
你可能需要执行的一些示例图操作:
- 例如,synsets16.txt 的每一行都包含了创建节点所需的信息。
- 例如,hyponyms16.txt 的每一行都包含一个或多个应该添加到相应节点的边的信息。
- 选择能够自然地帮助解决上述六个问题的实例变量和数据结构,会让你的开发工作事半功倍。
一些示例数据处理操作:
- 给定一个事物集合,你如何找到所有非重复项?(提示:有一种数据结构可以非常容易和高效地做到这一点)。 也别忘了善用搜索引擎,查阅你所选数据结构的文档。例如,如果你使用了 TreeMap,可以搜索“TreeMap methods java”、“Map methods java”或“Collection methods java”等关键词。
- 给定一个事物集合,如何对其进行排序?(提示:在 Google 上搜索你所用集合的排序方法。)
另外,提醒一下来自 proj2a:深度嵌套的泛型是一个警告信号,表明你正在做一些过于复杂的事情。 要么找到一种更简单的方法,要么创建一个辅助类/工具类来帮助管理复杂性。 例如,如果你发现自己尝试使用类似 Map<Set<Set<... 的东西,那么你已经开始走上一条不必要的艰难道路。
与往常一样,如果你的设计不顺利,难以取得进展,请不要害怕删除现有的实例变量并重新设计。 这个项目最难的部分是设计,而不是编程。 如果你确定你实际上喜欢它,你可以随时使用 git 恢复你的旧设计。
处理单词列表
例如,用户输入“change, occurrence”,我们应该只返回它们的共同下位词,即 [alteration, change, increase, jump, leap, modification, saltation, transition]。“Demotion”和“variation”未包含在内,因为它们并非同时是这两个词的下位词,特别是“occurrence”的下位词。
正如你所见,我们只希望返回同时属于列表中 所有 单词的下位词。 此外,请注意,用户提供的单词列表可以包含两个以上的单词,即使本规范中的示例没有。
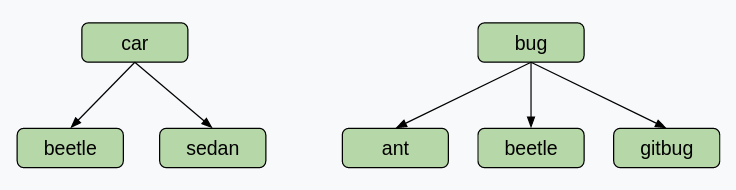
请注意,两个单词可能共享下位词,而无需一定共享节点。 看一下这个例子。 如果用户为下图输入“car, bug”,我们应该得到 [beetle],而不是 [](空列表)! 这个例子表明我们得到的是单词的交集,而不是节点的交集。
为了进一步演示此功能的实用性,假设我们使用完整的 synsets.txt 和 hyponyms.txt。
- 在单词框中输入“video, recording”并单击“Hyponyms”应显示
[video, video_recording, videocassette, videotape],因为这些都是“video”和“recording”的下位词。 - 在单词框中输入“pastry, tart”然后单击“Hyponyms”应显示
[apple_tart, lobster_tart, quiche, quiche_Lorraine, tart, tartlet ]。
task
修改 HyponymsHandler 以及你的其他代码,使其能够处理单词列表的情况。
为了测试这部分代码,建议使用 synsets16.txt 和 hyponyms16.txt 手动构建测试用例,并通过前端验证其正确性。
交付内容和评分
对于 Project 2B,唯一需要提交的成果除了 HyponymsHandler.java 文件外,还有所有辅助类。 然而,由于这些类的实现可能因人而异,我们不会直接对它们进行评分。
- Project 2B/C: Checkpoint:5 分 - 截止日期:3 月 15 日
- Project 2B 编码:50 分 - 截止日期:4 月 1 日
HyponymsHandler单字情形:50%,k = 0HyponymsHandler多字情形:30%,k = 0HyponymsHandlereecs-one-multi-word 情形:20%,k = 0(此测试针对单字和多字情形,但严格使用frequency-EECS.csv、hyponyms-EECS.txt和synonyms-EECS.txt。有关 EECS 课程列表的更多信息,请参见 2C。)
除了 Project 2B 之外,您还需要提交设计文档,这部分占 5 分,截止日期为 3 月 15 日。 设计文档的主要目的是为您的项目奠定基础。 编码之前进行充分的思考和设计至关重要。 我们希望在设计文档中看到以下内容:
- 明确您将在实现过程中使用哪些课堂上学过的数据结构。
- 您所实现算法的伪代码或总体思路。
您的设计文档长度应为 1-2 页。评分将主要基于您的努力程度、思考深度和完成情况。
请复制此模板并提交到 Gradescope。
即使之后您决定修改设计文档,也不必担心! 您可以随时更改。 我们希望您在编码之前认真思考实现方案,因此才要求您提交设计文档。
本项目的令牌限制策略如下:您将拥有 8 个令牌,每个令牌的刷新时间为 24 小时。
测试您的代码
我们在此项目的 proj2b/tests 目录中为您提供了两个简短的单元测试文件:
TestOneWordK0Hyponyms.javaTestMultiWordK0Hyponyms.java
提供的两个测试文件对应于您在此项目中解决的前两种情况,即:
- 查找 k = 0 时单个单词的下位词。
- 查找 k = 0 时多个单词的下位词(例如,
gallery, bowl)。
您需要完成 AutograderBuddy.java 文件,以便测试您的代码。 更多细节请参考提交您的代码部分。
这些测试文件并不完整; 实际上,每个文件仅包含一个基本的健全性测试。 您应该在这些文件中添加更多单元测试,并以此为模板,为相应的情形创建两个新的测试文件。
如果您需要帮助确定测试的预期输出,请使用我们在入门部分提供的两个工具。
调试提示
- 测试时尽量使用小文件!这样可以缩短运行
Main.java的启动时间,也更容易理解代码。如果您正在运行Main.java,这些文件的路径需要在main方法的前几行中进行设置。对于单元测试,文件名会作为参数传递给getHyponymsHandler方法。 - 您可以使用调试器运行
Main.java,以快速调试不同的输入。单击“Hyponyms”按钮后,您的代码将在调试器中执行 - 将触发断点,您可以使用变量窗口等。 - 这个项目涉及的内容很多。不要一开始就逐行调试。相反,先缩小范围,找出代码中哪个函数或区域无法正常工作,然后再仔细检查这些部分的代码。
- 查看 FAQ 了解常见问题。
提交您的代码
在本作业中,我们一直让您使用前端来测试您的代码。我们的评分程序无法模拟 Web 浏览器来调用你的代码。相反,我们需要您在 proj2b.src.main.AutograderBuddy 类中提供一个方法,该方法提供一个可以处理下位词请求的处理程序。
当您在本规范开始时运行 git pull skeleton main 时,您应该会收到一个名为 AutograderBuddy.java 的文件。
打开 AutograderBuddy.java 并填写 getHyponymsHandler 方法,使其返回一个使用给定四个文件的 HyponymsHandler。你在这里写的代码应该和 Main.java 里的代码很相似。
现在您已经创建了 proj2b.src.main.AutograderBuddy,您可以提交给自动评分器。如果您未能通过任何测试,您应该能够通过在上面的测试文件上构建,在本地将它们复制为 JUnit 测试。如果需要任何其他数据文件,它们将作为链接添加到此部分。
致谢
本作业中关于 WordNet 的部分,主要参考并改编自 Alina Ene 和 Kevin Wayne 在普林斯顿大学的 Wordnet 作业。