Project 2C Ngordnet Enhancements
常见问题解答
每个作业的顶部都会提供一个常见问题解答的链接。您也可以通过在网址末尾添加“/faq”来访问。项目 2C 的常见问题解答请见此处。
检查点和设计文档的截止日期:2024年3月15日
编码截止日期:2024年4月1日
在这个项目中,你将完成 NGordnet 中 k!=0 和 commonAncestors 功能的实现。
由于这是一个较新的项目,规范中可能偶尔会出现错误或令人困惑的地方。如果您发现任何类似问题,请在 Ed 上发帖。
在开始 2C 之前,请务必仔细阅读 2B 规范。
项目设置
此项目的设置与其他实验/项目有所不同。请不要跳过此步骤!
框架设置
- 与本课程的其他作业类似,运行
git pull skeleton main来获取此项目的框架代码。- 注意:您会发现此框架与项目 2B 的框架几乎完全相同。这是故意的。
- 通过此链接下载此项目的
data文件,然后将它们移动到与src目录同级的proj2c目录中。 - 将您在 2A 中实现的
ngrams(包括TimeSeries和NGramMap) 复制到proj2c目录中。 - 将您在 2B 中实现的代码复制到
proj2c目录中,因为k!=0和commonAncestors的实现依赖于您在 2A 和 2B 中的代码。
完成后,您的 proj2c 目录结构应如下所示:
proj2c
├── data
│ ├── ngrams
│ └── wordnet
├── src
│ ├── <2B 辅助文件>
│ ├── browser
│ ├── main
│ ├── ngrams
│ │ ├── <您在 2A 中实现的 NGramMap>
│ │ └── <您在 2A 中实现的 TimeSeries>
│ └── plotting
├── static
└── tests
虽然您可以(并且应该!)提前设计 2C,但为了避免您的实现中出现任何潜在的错误,我们建议仅在您在项目 2B 中获得满分后才开始编码。
开始
该项目的一部分旨在帮助您为您的实现制定一个高效且正确的设计方案。您制定的设计方案对于处理这些情况至关重要。在开始撰写设计文档之前,请仔细阅读 2B 和 2C 规范。
我们可以使用(而且强烈建议!)使用我们创建的两个实用工具来探索数据集,观察参考答案在特定输入下的表现,并获得单元测试的预期输出(参见测试你的代码)。相关工具的链接也会在文档的其他部分提供。
- Wordnet Visualizer: 通过可视化方式理解同义词集 (synset) 和下位词的概念,并测试不同的单词或单词列表,以用于潜在的测试用例输入。点击 "?" 气泡可了解如何使用该工具的各项功能!
- 参考答案网页: 用于生成各种测试用例输入的预期输出。利用此网页编写单元测试!
task
通读整个 2B/C 规范并完成 Project 2B/C: Checkpoint
完成 checkpoint 后,完成 设计文档
处理 k != 0
在 Project 2B 中,我们处理了 k == 0 的情况,这是用户未输入 k 值时的默认值。
你的任务是处理用户输入 k 值的情况。k 代表了我们希望在输出结果中包含的最大下位词数量。例如,如果用户输入单词 "dog",并且指定 k = 5,那么你的代码最多返回 5 个单词。
为了选择这 5 个下位词,你需要返回在指定时间范围内出现频率最高的 k 个单词。例如,如果输入为 words = ["food", "cake"],startYear = 1950,endYear = 1990,且 k = 5,那么你需要找出在该时间段内,既是 "food" 又是 "cake" 的下位词,并且出现频率最高的 5 个单词。其中,"流行度" 指的是该单词在整个指定时间段内出现的总次数。然后,按照字母顺序返回这些单词。例如,如果使用 top_14377_words.csv、total_counts.csv、synsets.txt 和 hyponyms.txt 这些数据文件,那么结果应该是 [cake, cookie, kiss, snap, wafer]。
务必确保你获取的是出现次数 (counts) 最多的单词,而不是权重 (weights) 最高的单词。否则,你可能会遇到难以调试的问题!
请注意,如果前端没有提供年份,NGordnetQueryHandler.readQueryMap 会提供 startYear = 1900 和 endYear = 2020 的默认值。
考虑到 k != 0 时,确定单词的下位词可能比较困难,我们提供了一份更易于理解的数据集!以下展示了一个根据 EECS 课程要求修改的版本,其灵感来源于 HKN。同时,我们也提供了用于表示下方图表的数据文件(frequency-EECS.csv、hyponyms-EECS.txt、synsets-EECS.txt)。例如,如果输入为 words = ["CS61A"],startYear = 2010,endYear = 2020,且 k = 4,那么你应该得到 "[CS170, CS61A, CS61B, CS61C]"。请注意,frequency-EECS.csv 文件与之前的文件略有不同,因为它包含具有相同频率的值。我们强烈建议你仔细研究 frequency-EECS.csv 文件。此外,在设计实现方案时,请记住我们可能会提供具有相同频率的单词作为输入。
如果在指定时间范围内,某个词的计数为零,则不应返回。也就是说,当 k > 0 时,不应显示任何未出现在 ngrams 数据集中的词。
如果没有计数非零的词,则应返回一个空列表,即 []。
如果计数非零的词少于 k 个,则仅返回这些词。例如,如果输入单词 "potato" 并输入 k = 15,但只有 7 个 "potato" 的下义词具有非零计数,则只会返回 7 个词。
这个任务会比较棘手,因为你需要考虑如何传递信息,使 HyponymsHandler 能够访问有效的 NGramMap。
task
修改你的
HyponymsHandler和实现的其余部分,以处理k != 0的情况。
在线参考程序上没有 EECS 课程指南,因此如果你提供输入 CS61A,它将不会返回任何内容。
不要为此任务创建静态 NGRAMMAP! 直接创建一个
public static NGramMap似乎很方便,这样就能在代码的任何地方访问它。
我们不推荐这种编程思路,建议你将 NGramMap 对象通过构造函数或方法传入。 我们将在软件工程讲座中再来讨论这个问题。
提示
- 在使用自动评分器之前,建议你先构建自己的测试用例。 我们在上一节中提供了一个:
words = ["food", "cake"],startYear = 1950,endYear = 1990,k = 5。 - 在构建自己的测试用例时,请考虑创建自己的输入文件。 使用我们提供的大型输入文件非常繁琐。
查找共同祖先
到目前为止,我们只关心查找单词的共同下义词。 本项目的最后一部分,你需要找到共同祖先。
也就是说,对于给定的一组词,哪些词包含了这组词作为其下义词?
例如,考虑来自 2B 的 synsets16.txt 和 hyponyms16.txt:

如果查找 "adjustment" 的祖先,应该得到 "[adjustment, alteration, event, happening, modification, natural_event, occurrence, occurrent]",如下图所示:

这也应该适用于多种上下文中的单词,如 "change" 所示:

"change" 的祖先应该是 "[act, action, alteration, change, event, happening, human_action, human_activity, modification, natural_event, occurrence, occurrent]"。
我们还可以询问单词集的共同祖先,这可以揭示一些巧妙的关系!
 在这里,我们寻找词汇
在这里,我们寻找词汇 ["change", "adjustment"] 的共同祖先。结果应为 "[alteration, event, happening, modification, natural_event, occurrence, occurrent]",这些是图中同时包含 "change" 和 "adjustment" 作为下位词的所有词汇。请注意,"alteration" 和 "modification" 也包含在结果中,这可能与您预期的不同,原因如下。
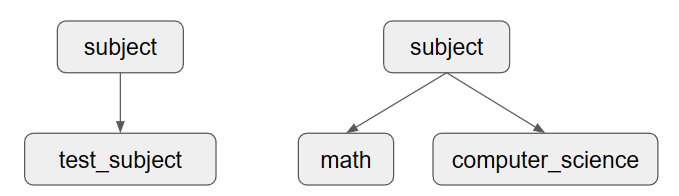
注意:请务必像 2B 中一样,采用词汇交集而不是节点交集。因此,在下图中,["test_subject", "math"] 的共同祖先应该返回 "[subject]",因为 "subject" 包含 "test_subject" 和 "math" 作为下位词,即使 "test_subject" 和 "math" 在图中没有直接关联。
我们还可以查询三个或更多词汇的共同祖先。
请注意,输出按字母顺序排列,并请记住 k != 0 也适用于此任务。
您的查询处理需要对共同祖先的查找保持高效(即,应用于 2B 的超时仍然适用)。 这意味着,如果遍历每个词汇,并检查其是否包含查询中的所有词汇作为下位词,那么在大规模数据集上速度会非常慢!
NgordnetQueryType
task
您需要修改 HyponymsHandler 类,以根据查询的类型进行处理,查询类型包括下位词查询和共同祖先查询。 这类似于您获取 startYear、endYear 或 k 的方式。查询类型将分别由 NgordnetQueryType.HYPONYMS 或 NgordnetQueryType.ANCESTORS 指定。
task
修改您的
HyponymsHandler和其他相关代码,以处理共同祖先查询和下位词查询。
设计技巧
如前所述,您无需复制粘贴代码或进行任何过于剧烈的操作来处理此任务。 考虑如何使用之前相同的数据结构和方法来解决此问题,也许只需进行一些调整。
辅助方法是您的好帮手! 如果您发现需要多次编写相似的代码,请考虑创建一个辅助方法,以便在多个地方调用,从而避免重复劳动。
交付内容和评分
对于 Project 2C,唯一需要提交的是 HyponymsHandler.java 文件以及任何辅助类。 但是,我们不会直接对这些类进行评分,因为不同学生的实现方式可能有所不同。
- Project 2B/C:检查点:5 分 - 截止日期 3 月 15 日
- Project 2C 编码:25 分 - 截止日期 4 月 1 日
HyponymsHandlerpopularity-hardcoded:20%,k != 0HyponymsHandlerpopularity-randomized:30%,k != 0HyponymsHandlercommon-ancestors:50%
除了 Project 2C 之外,您还必须提交您的设计文档。 这将价值 5 分,截止日期为 3 月 15 日。 设计文档的主要目的是作为您项目的基础。 在编码之前进行思考和构思非常重要。 我们在设计文档中寻找的内容:
- 确定您将在实现中使用的我们在课堂上学到的数据结构。
- 用于实现的算法的伪代码/总体概述。
您的设计文档应约为 1 - 2 页。 设计文档的评分主要基于努力程度、思路和完整性。 请复制此模板,并提交到 Gradescope。
之后如果决定修改设计文档,不用担心,可以随时修改!我们希望大家在编写代码前认真思考设计方案,所以才要求提交设计文档作为项目的一部分。
这个项目的令牌限制如下:你将有 8 个令牌,每个令牌的刷新时间是 24 小时。
测试你的代码
我们在这个项目的 proj2c/tests 目录下提供了两个简单的单元测试文件:
TestOneWordKNot0Hyponyms.javaTestCommonAncestors.java
这些测试文件并不完整;实际上,每个文件只有一个基本的正确性测试。你应该在每个文件中添加更多的单元测试,也可以把它们作为模板,为不同的情况创建新的测试文件。
如果需要帮助来确定测试的预期输出,可以使用我们在入门部分提供的两个工具。
调试技巧
- 在测试时使用小文件!这减少了运行
Main.java的启动时间,并且更容易推理代码。如果你正在运行Main.java,这些文件在main方法的前几行中设置。对于单元测试,文件名被传递到getHyponymsHandler方法中。 - 你可以使用调试器运行
Main.java来快速调试不同的输入。点击 "Hyponyms" 按钮后,你的代码会在调试器中运行 - 触发断点,你可以使用变量窗口等等。 - 这个项目有很多移动部件。不要从逐行调试开始。而是缩小范围,找到哪个函数或代码区域工作不正常,然后在这些代码行中仔细检查。
- 查看 FAQ 了解常见问题和疑问。
提交你的代码
在这个作业中,我们一直让大家使用前端来测试代码。我们的评分器还不够智能,无法模拟网页浏览器来调用你的代码。因此,你需要在 proj2c_testing.AutograderBuddy 类中提供一个方法,这个方法要返回一个能够处理下位词请求的处理程序。
像 2B 一样,打开 AutograderBuddy.java 文件,填写 getHyponymsHandler 方法,让它返回一个 HyponymsHandler 实例,这个实例要使用给定的四个文件。你在这里写的代码可能和 Main.java 里的代码很相似。
现在你已经创建了 proj2c.testing.AutograderBuddy,你可以提交到自动评分器。如果你未能通过任何测试,你应该能够通过构建上面的测试文件,在本地将它们复制为 JUnit 测试。如果需要任何其他数据文件,它们将作为链接添加到此部分。
可选的额外功能
如果你想在此项目中更进一步(甚至探索一些前端开发),请阅读可选功能规范!
致谢
这个作业中关于 WordNet 的部分,是参考并改编自 Alina Ene 和 Kevin Wayne 在普林斯顿大学的 Wordnet 作业。