Lab 08 Hashmaps
常见问题解答
本实验的常见问题解答可以在这里找到。
介绍
在本实验中,你将实现MyHashMap类,它是基于哈希表的Map61B接口的一个实现。这与Lab 06 非常相似,不同之处在于这次我们要实现的是 HashMap,而不是 TreeMap。
完成实现后,你需要将 MyHashMap 的性能与基于列表实现的 ULLMap 以及 Java 内置的 HashMap (同样基于哈希表) 进行比较。 我们还将比较MyHashMap在使用不同的数据结构作为桶时的性能。
MyHashMap
概述
我们已经在MyHashMap.java中创建了一个类MyHashMap,其中包含非常少的初始代码。 你的目标是实现MyHashMap继承的Map61B接口中的所有方法,除了 remove、keySet和iterator(Lab 08可选)。 对于这些方法, 可以直接抛出 UnsupportedOperationException 异常。
请注意,在实现Map61B的所有方法之前,你的代码将无法编译。 你可以先编写所有必需的方法签名,然后逐个实现。在完成具体实现之前,可以先为这些方法抛出 UnsupportedOperationException 异常。
快速回顾动画
以下是一个哈希表如何工作的快速动画。 N指的是哈希表中的项目数,M指的是桶的数量。
我们通过将对象的 hashCode 值对桶的数量取模 (%),来确定该对象 (用形状表示) 应该放入哪个桶。 当达到负载因子时,我们将桶的数量乘以调整大小因子,并重新哈希所有项目,并对新的桶数取模。
对于下面的视频动画,哈希函数是任意的,并为每个输入的形状(对象)输出一个随机整数。
感谢 Meshan Khosla 制作了这个动画!
骨架代码
你可能还记得在课堂上,当我们构建哈希表时,我们可以选择许多不同的数据结构作为桶。 经典方法是选择LinkedList。 但我们也可以选择ArrayList、TreeSet,甚至其他更疯狂的数据结构,如PriorityQueue,甚至是其他HashSet!
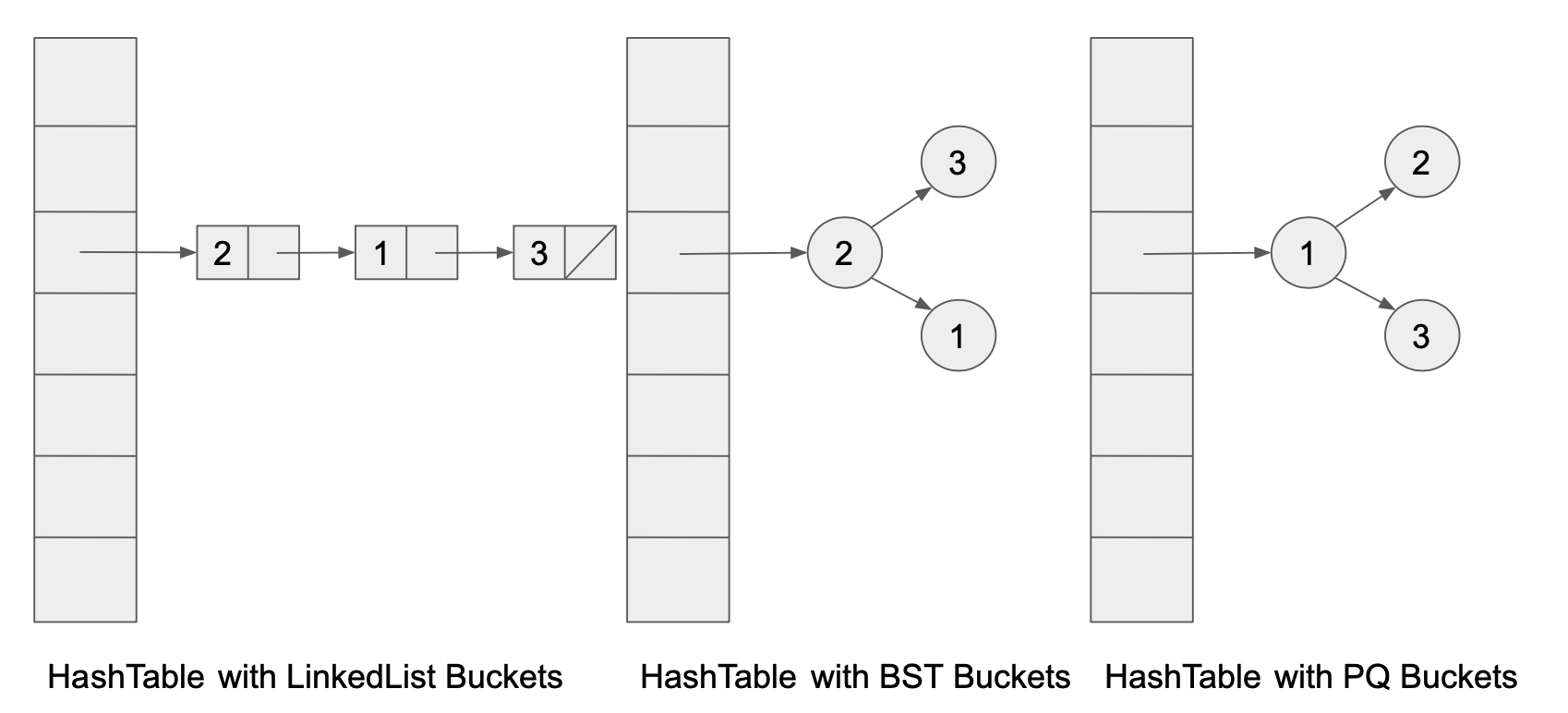
在本实验中,我们将尝试使用不同数据结构的哈希表作为每个桶,并通过经验来观察使用不同的数据结构作为哈希表桶之间是否存在渐近差异。
在本实验中,我们将尝试LinkedList、ArrayList、HashSet、Stack和ArrayDeque(不幸的是,由于过多的样板代码,没有像上图所示的TreeSet或PriorityQueue,但如果你愿意,欢迎尝试)。 这有很多类!
可以想象,如果实现 MyHashMap 时不够仔细,要修改桶的类型就需要花费大量精力进行查找和替换。 例如,如果我们想将所有ArrayList桶更改为LinkedList桶,我们将不得不查找+替换所有出现的ArrayList,并将其替换为LinkedList。 这样做并不理想。例如,可能存在某些非桶组件依赖于 ArrayList 的特定方法。 我们不想通过将其更改为LinkedList来破坏我们的代码!
初始代码的目的是为了更方便地使用 MyHashMap 尝试不同的桶类型。 这一点是通过多态和继承实现的,而我们已经在之前的课程中学习过这些概念。 它还使用了工厂方法和类,它们是用于创建对象的实用程序代码。 这是处理更高级代码时的一种常见模式,尽管这些细节超出了61B的范围。
MyHashMap通过使用哈希表来实现Map61B接口。 在初始代码中,我们给出了实例变量
private Collection<Node>[] buckets,它是哈希表的底层数据结构。 让我们来分析一下这段代码的含义:
buckets是MyHashMap类中的一个private变量。
private Collection<Node>[] buckets;
- 它是一个
Collection<Node>对象的数组 (或表),其中每个Collection都代表哈希表中的一个桶,并且存储Node对象。 Node是我们给出的一个私有(嵌套)辅助类,用于存储单个键值映射。 此类的初始代码应该很容易理解,并且不需要任何修改。
protected class Node {
K key;
V value;
Node(K k, V v) {
key = k;
value = v;
}
}
java.util.Collection是一个接口,大多数数据结构都继承自它,用于表示一组对象。Collection接口支持诸如add、remove和iterator之类的方法。java.util中的许多数据结构都实现了Collection,包括ArrayList、LinkedList、TreeSet、HashSet、PriorityQueue等等。请注意,由于这些数据结构实现了Collection,我们可以使用多态性将它们分配给静态类型为Collection的变量。- 因此,我们的
Collection<Node>数组可以使用多种数据结构实例化。请确保你的桶能够适用于任何 Collection 类型! 有关如何执行此操作,请参见下面的警告。 - 在 Java 中创建
Collection<Node>[]数组并将其存储在buckets变量中时,请注意无法创建参数化类型的数组。Collection<Node>是一种参数化类型,因为我们使用Node类参数化了Collection类。因此,Java 不允许new Collection<Node>[size],对于任何给定的size。如果您尝试这样做,您将收到“泛型数组创建错误”。
为了解决这个问题,应该创建 new Collection[size],其中 size 代表所需大小。
Collection[]的元素可以是任何类型的集合,例如Collection<Integer>或Collection<Node>。就本实验而言,我们只会向Collection[]中添加Collection<Node>类型的元素。
哈希表通过工厂方法 protected Collection<Node> createBucket() 来实现不同类型的桶,该方法返回一个 Collection 对象。对于 MyHashMap.java,您可以选择任何您喜欢的数据结构。例如,如果您选择 LinkedList,则 createBucket 的主体将只是:
protected Collection<Node> createBucket() {
return new LinkedList<>();
}
您必须使用 createBucket 方法来创建新的桶数据结构,而不是使用 new 运算符。初看之下可能觉得没有用处,但它允许我们的工厂类覆盖 createBucket 方法,以便提供不同的数据结构作为每个桶。
在 MyHashMap 中,你可以让该方法返回一个新的 LinkedList 或 ArrayList 实例。
实现要求
您应该实现以下构造函数:
public MyHashMap();
public MyHashMap(int initialCapacity);
public MyHashMap(int initialCapacity, double loadFactor);
以下是 MyHashMap 的一些附加要求:
- 您的哈希映射最初应具有等于
initialCapacity的桶数。当负载因子超过最大loadFactor阈值时,应该增加MyHashMap的容量。回想一下,当前的负载因子可以计算为loadFactor = N/M,其中N是映射中的元素数,M是桶数。负载因子表示每个桶中的平均元素数。如果未给出initialCapacity和loadFactor,则应设置默认值initialCapacity = 16和loadFactor = 0.75(如 Java 的 内置 HashMap 所做的那样)。 - 您应该使用单独的链接来处理冲突。除了桶类、
Collection、Iterator、Set和HashSet之外,您不应使用任何库。有关如何实现单独链接的更多详细信息,请参见上面的骨架代码部分。 - 因为我们使用
Collection<Node>[]作为我们的buckets,所以在实现MyHashMap时,您仅限于使用Collection接口指定的方法。当您在Collection中搜索Node时,迭代Collection,并找到其key与所需键.equals()的Node。 - 如果同一个键被插入多次,则每次都应更新该值(即,不应添加
Node)。您可以假设永远不会插入null键。 - 调整大小时,请确保以乘法(几何)方式调整大小,而不是以加法(算术)方式调整大小。您不需要缩小大小。
- 假设插入的任何对象的
hashCode都能很好地分散数据(回想一下:Java 中的每个Object都有自己的hashCode()方法),MyHashMap操作都应该是恒定的摊销时间。
hashCode() 可以返回一个负值!Java 的取模运算符 % 对于负数输入会返回负值,但我们需要将元素放入 范围内的桶中。有很多方法可以处理这个问题:
- (推荐)您可以使用
Math.floorMod()来代替%进行取模运算。它具有非负的值范围,类似于 Python 的取模。 - 如果
%运算的结果是负数,你可以加上数组的长度来修正它。 - 您可以使用
Math.abs()函数将负值转换为正值。请注意,, 和 通常并不等价!我们在这里使用取模运算只是为了确保我们有一个有效的索引。我们不必过于关心元素落入哪个具体的桶,因为好的哈希函数应该能够将元素均匀地分布在正数和负数范围内。 - 选项 (3),使用位掩码 (如果对此不熟悉,不必担心)。这超出了 61B 课程的范围,但有些资料会用到,所以我们在此提及。
根据 Map61B 中的规范和上述指南完成 MyHashMap 类。
资源
以下资源可能会对您有所帮助
- 讲座幻灯片:
以下内容可能包含过时的代码或使用不熟悉的技术,但仍然应该有用:
ULLMap.java(已提供),一个基于无序链表的Map61B实现
测试
您可以使用 TestMyHashMap.java 测试您的实现。一些测试非常棘手,并且做了我们在 61B 中没有学过的奇怪的事情。注释会帮助你理解测试的具体内容。
如果您正确地实现了泛型 Collection 桶,那么您也应该通过 TestMyHashMapBuckets.java 中的测试。TestMyHashMapBuckets.java 文件只是为每个实现不同桶数据结构的 map 子类调用 TestMyHashMap.java 中的方法。确保您使用提供的工厂方法(即 createBucket)正确实现了 MyHashMap,以便 TestHashMapBuckets.java 通过。
如果您选择实现额外的 remove、keySet 和 iterator 方法,我们会在 TestHashMapExtra.java 中提供一些测试。
速度测试
InsertRandomSpeedTest.java 和 InsertInOrderSpeedTest.java 中提供了两个交互式速度测试。在完成 MyHashMap 之前,请勿尝试运行这些测试。准备就绪后,您可以在 IntelliJ 中运行测试。
InsertRandomSpeedTest 类对您的 MyHashMap、ULLMap(已提供)和 Java 内置 HashMap 的元素插入速度执行测试。它会要求用户输入大小 N,然后生成 N 个长度为 10 的字符串,并将它们作为 <String, Integer> 键值对插入到 Map 中。
试试看,与简单的实现和工业级的实现相比,你的数据结构性能如何随 N 变化。将您的结果记录在提供的名为 src/results.txt 的文件中。您的结果没有标准格式要求,也没有所需的数据点数量。我们希望您至少写一两句话来描述您的观察结果。
现在尝试运行 InsertInOrderSpeedTest,它的行为类似于 InsertRandomSpeedTest,但这次 <String, Integer> 键值对中的 String 以字典顺序递增插入。您的代码应该与 Java 的内置解决方案大致相同——比如说,在 10 倍左右的范围内。这告诉我们,与最先进的 TreeMaps 相比,最先进的 HashMaps 相对容易实现。考虑一下 BSTMap/TreeMap 和其他数据结构之间的这种关系 - 是否存在 Hashmap 可能更好的某些实例?和你的同学讨论这个问题,并将你的思考结果添加到 results.txt 中。
不同的桶类型
如果您正确地实现了泛型 Collection 桶,那么大部分工作就完成了!我们可以直接比较用于实现桶的不同数据结构。我们提供了 speed/BucketsSpeedTest.java,这是一个交互式测试。它首先会询问用户一个整数 L,作为后续操作中字符串的长度。然后,在一个循环中,它会询问用户一个整数 N,并使用不同类型的桶来测试你的 MyHashMap 的速度。
尝试一下,比较不同的实现如何随 N 缩放。和你的同学讨论你的测试结果,并将你的分析记录在 results.txt 中。
你可能已经注意到,当使用 HashSet 作为桶时,我们的实现是通过迭代整个数据结构来搜索 Node 的。但我们知道,哈希表本身应该支持更高效的查找方式。如果我们能够利用 HashSet 本身的常数时间查找特性,我们的哈希表在渐近意义上性能是否会提升呢? 这里不需要进行任何新的代码实现,只需和同学讨论,并将你的想法记录在 results.txt 中即可。
任务:
在 speed 目录下运行上述速度测试,并将你的结果记录在 results.txt 中。
交付内容和评分
本次实验总分为 5 分。Gradescope 上有一个隐藏测试(检查你的 results.txt)。其余的测试都是本地的。如果你通过了所有本地测试并充分填写了 results.txt 文件,你将在 Gradescope 上获得满分。
以下各项各占 分,并且分别对应一个单元测试:
- 泛型
clearcontainsKeygetsizeput- 功能实现
- 调整容量
- 边界情况
- 桶(所有
TestMyHashMapBuckets中的测试) results.txt(不在本地测试,但在 Gradescope 自动评分器上测试)
如前所述,如果你不实现可选练习,抛出一个 UnsupportedOperationException 异常,如下所示:
throw new UnsupportedOperationException();
提交
和之前的作业一样,请添加、提交并将你的 Lab 08 代码推送到 GitHub。然后,提交到 Gradescope 以测试你的代码。
可选练习
这些将不会被评分,但你仍然可以通过给定的测试获得反馈。
在你的 MyHashMap 类中实现方法 remove(K key) 和 remove(K key, V value)。作为额外的挑战,尝试在不使用额外实例变量存储键集合的情况下实现 keySet() 和 iterator() 方法。
对于 remove,如果参数键在 MyHashMap 中不存在,你应该返回 null。否则,删除键值对 (key, value) 并返回关联的值。