讨论 4 | CS 61A 2024 年春季学期
讨论 4:树形递归
选你们小组的一位成员加入 Discord。 多个人加入也行,但一个人就够了。
现在请切换到 Pensieve:
- 所有人:请前往 discuss.pensieve.co 并使用您的 @berkeley.edu 邮箱登录,然后输入您的组号。(您的组号是您的 Discord 频道号。)
进入 Pensieve 后,就无需返回此页面了;Pensieve 具有所有相同的内容(但具有更多功能)。 如果 Penseive 因为某些原因无法正常工作,请返回此页面并继续讨论。
如果遇到问题,请在 Discord 的 #help 频道里发帖求助。
开始
为了配合今天树形递归的主题,请说出你的名字,并分享你最喜欢的树(可以是具体的树,也可以是树的种类)。 (树形递归函数是多次调用自身的函数。)
在本次讨论中,请先不要使用 Python 解释器运行代码,除非你确信你的解决方案是正确的。 通过思考你的代码会做什么来弄清楚并检查你的答案。 不确定? 与你的小组讨论!
[新增] 如果你们小组不足 4 人,可以和同教室的其他小组合并。
[新增] 递归是需要练习的。 如果你在编写递归函数时感到吃力,请不要灰心。 相反,每次你解决一道题(即使有帮助或者在小组里完成的),都请记下为了取得进展,你领悟到了什么。 学生通过实践和反思来提高。
[有趣] 这个戴牛仔帽的人的表情符号是有效的 Python 代码:o[:-D]
>>> o = [2, 0, 2, 4]
>>> [ o[:-D] for D in range(1,4) ]
[[2, 0, 2], [2, 0], [2]]
🤠
树形递归
对于以下问题,不要立即开始尝试编写代码。 而是首先用文字描述递归情况。 一些例子:
- 在讲座中的
fib中,递归情况是将前两个斐波那契数相加。 - 在实验中的
double_eights中,递归情况是检查数字的其余部分中是否存在双 8。 - 在讲座中的
count_partitions中,递归情况是使用最大为m的部分对n-m进行分区以及使用最大为m-1的部分对n进行分区。
Q1:昆虫组合学
一只昆虫在一个 m 乘 n 的网格内。 昆虫从左下角 (1, 1) 开始,想要到达右上角 (m, n)。 昆虫只能向上或向右移动。 编写一个函数 paths,该函数接受网格的高度和宽度,并返回昆虫可以从起点到终点所采取的路径数。 这个问题虽然有一个 封闭形式的解,但请尝试用递归方法来解决。
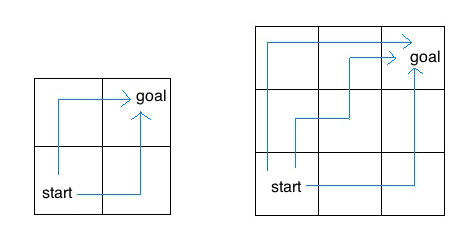
在 2 乘 2 的网格中,昆虫有两条从起点到终点的路径。 在 3 乘 3 的网格中,昆虫有六条路径(上面仅显示了三条)。
提示: 如果昆虫到达网格的上边缘或最右边缘会发生什么?
你的答案
在 61A 代码中运行
解决方案
def paths(m, n):
"""返回从一个 M 乘 N 网格的某个角到其对角的路径数。
>>> paths(2, 2)
2
>>> paths(5, 7)
210
>>> paths(117, 1)
1
>>> paths(1, 157)
1
"""
if m == 1 or n == 1:
return 1
return paths(m - 1, n) + paths(m, n - 1)
# Base case: Look at the two visual examples given. Since the insect
# can only move to the right or up, once it hits either the rightmost edge
# or the upper edge, it has a single remaining path -- the insect has
# no choice but to go straight up or straight right (respectively) at that point.
# There is no way for it to backtrack by going left or down.
递归的情况是,总路径数等于从右边相邻格子 (m, n-1) 到达终点的路径数,加上从上边相邻格子 (m-1, n) 到达终点的路径数。
演示环节: 小组达成一致方案后,请练习如何清晰地阐述递归逻辑。选出一位演示者,然后向 discuss-queue 频道发送一条带有 @discuss 标签、你们讨论小组号码以及消息 "Here's the path!" 的消息,课程工作人员将加入你们的语音频道,听取你们的描述并提供反馈。
列表的树递归
[新内容] 你们中的一些人已经知道我们尚未涵盖的列表操作,例如 append。今天不要使用它们。只需要使用列表字面量(如 [1, 2, 3])、元素选择(如 s[0])、列表相加(如 [1] + [2, 3])、len 函数和切片操作(如 s[1:])。使用这些!下周介绍其他列表操作时,会有充足的时间。
关于列表,最重要的事情是记住,一个非空列表 s 可以被分成它的第一个元素 s[0] 和列表的其余部分 s[1:]。
>>> s = [2, 3, 6, 4]
>>> s[0]
2
>>> s[1:]
[3, 6, 4]
Q2:最大乘积
实现 max_product,它接受一个数字列表,并返回可以通过将列表中的非连续元素相乘而形成的最大乘积。假设输入列表中的所有数字都大于或等于 1。
你的答案
在 61A 代码中运行
解决方案
def max_product(s):
"""返回 s 的非连续元素的最大乘积。
>>> max_product([10, 3, 1, 9, 2]) # 10 * 9
90
>>> max_product([5, 10, 5, 10, 5]) # 5 * 5 * 5
125
>>> max_product([]) # 没有数字的乘积是 1
1
"""
if s == []:
return 1
if len(s) == 1:
return s[0]
else:
return max(s[0] * max_product(s[2:]), max_product(s[1:]))
# OR
return max(s[0] * max_product(s[2:]), s[1] * max_product(s[3:]))
首先尝试将第一个元素乘以第一个元素之后所有元素的 max_product(跳过第二个元素,因为它与第一个元素是连续的),然后尝试跳过第一个元素并找到其余元素的 max_product。使用 max 函数来确定哪个结果更大。
获得帮助的好方法是与课程工作人员交谈!
这个解法的思路是考虑是否包含 s[0] 在乘积中。
- 如果我们包含
s[0],则不能包含s[1]。 - 如果我们不包含
s[0],则可以包含s[1]。
递归情况是我们选择以下两者中较大的一个:
- 将
s[0]乘以跳过s[1]后的s[2:]的最大乘积,或者 - 仅计算跳过
s[0]后的s[1:]的最大乘积。
以下是将这些概念转化为代码的一些关键点:
- 内置的
max函数可以找到两个数字中较大的一个,在本例中,这两个数字来源于两次递归调用。 - 在任何情况下,
max_product函数都会接收一个数字列表作为输入,并返回一个数字作为结果。
这种递归情况的表达式是:
max(s[0] * max_product(s[2:]), max_product(s[1:]))
由于此表达式从不引用 s[1],并且即使对于单元素列表 s,s[2:] 的计算结果也为空列表,因此如果使用此递归情况,则可以省略第二个基本情况 (len(s) == 1)。
上述递归解法探索了一些我们预先知道并非最优的选项,例如同时跳过 s[0] 和 s[1]。 或者,递归情况可以是在以下两者中选择较大者:
- 将
s[0]乘以s[2:]的max_product(跳过s[1]);或者 - 将
s[1]乘以s[3:]的max_product(跳过s[0]和s[2])。
此递归情况的表达式为:
max(s[0] * max_product(s[2:]), s[1] * max_product(s[3:]))
请共同完成以下句子,并将答案输入到你们小组的频道文本聊天中。“递归的情况是选择较大的……和……”
Q3:求和组合
实现 sums(n, m),它接受总数 n 和最大值 m。 它返回所有列表的列表:
- 总和为
n, - 仅包含高达
m的正数,并且 - 其中没有两个相邻的数字相同。
应该返回所有包含相同数字但顺序不同的列表。
以下是一种符合以下模板的递归方法:通过构建所有总和为 n 且以 k 开头的列表来构建 result 列表,对于从 1 到 m 的每个 k。 例如,sums(5, 3) 的结果由三个列表组成:
[[1, 3, 1]]以 1 开头,[[2, 1, 2], [2, 3]]以 2 开头,并且[[3, 2]]以 3 开头。
提示: 使用 [k] + s 表示数字 k 和列表 s 来构建一个以 k 开头然后具有 s 的所有元素的列表。
>>> k = 2
>>> s = [4, 3, 1]
>>> [k] + s
[2, 4, 3, 1]
你的答案
在 61A 代码中运行
解决方案
def sums(n, m):
"""返回所有总和为 n 的列表,列表中的元素为不超过 m 的正整数,且任意两个相邻元素均不相同。
>>> sums(5, 1)
[]
>>> sums(5, 2)
[[2, 1, 2]]
>>> sums(5, 3)
[[1, 3, 1], [2, 1, 2], [2, 3], [3, 2]]
>>> sums(5, 5)
[[1, 3, 1], [1, 4], [2, 1, 2], [2, 3], [3, 2], [4, 1], [5]]
>>> sums(6, 3)
[[1, 2, 1, 2], [1, 2, 3], [1, 3, 2], [2, 1, 2, 1], [2, 1, 3], [2, 3, 1], [3, 1, 2], [3, 2, 1]]
"""
if n < 0:
return []
if n == 0:
sums_to_zero = [] # The only way to sum to zero using positives
return [sums_to_zero] # Return a list of all the ways to sum to zero
result = []
for k in range(1, m + 1):
result = result + [[k] + rest for rest in sums(n-k, m) if rest == [] or rest[0] != k]
return result
k 是构成总和为 n 的列表的第一个数字,rest 是列表的剩余部分,所以目标是构建这样一个总和为 n 的列表。
调用 sums 函数来构建所有总和为 n-k 的列表。通过在这些列表的前面添加 k,就可以构造出总和为 n 的列表。
这里保证“没有两个相邻的数字相同”。 因为 k 是当前构建的列表的第一个数字,所以它不能和 rest 列表的第一个元素相同(rest 列表的第一个元素将成为新列表的第二个数字)。
递归的情况是:任何总和为 n 的列表,都可以看作是一个整数 k (最大为 m),后面跟着一个总和为 n-k 且不以 k 开头的列表。
以下是一些将上述逻辑转化为代码的关键点:
- 如果
rest是[2, 3],则[1] + rest是[1, 2, 3]。 - 在表达式
[... for rest in sums(...) if ...]中,rest会依次被赋值为每次递归调用sums(...)所返回的列表中的每一个子列表。 举例来说,如果调用sums(3, 2),那么rest会先被赋值为[1, 2],然后被赋值为[2, 1]。
在给出的解决方案中,下面的表达式会创建一个列表的列表,其中每个子列表都以 k 开头,后面跟着 rest 列表中的元素。 表达式首先会检查 rest 列表是否也以 k 开头(如果 rest 以 k 开头,那么新生成的列表就会出现两个相邻的 k)。
例如,在 sums(5, 2) 的调用中,当 k 等于 2 时,递归调用 sums(3, 2) 会首先把 rest 赋值为 [1, 2],因此 [k] + rest 的结果是 [2, 1, 2]。 接下来,rest 会被赋值为 [2, 1],但由于 if 条件的限制,这种情况会被跳过,从而避免生成 [2, 2, 1] 这样的包含两个相邻的 2 的列表。
你可以使用递归可视化工具来逐步分析 sums(5, 3) 的调用过程。
如果遇到困难,欢迎在 Discord 上发帖求助,我们的工作人员会及时解答!
完成签到
请大家填写出勤表(每人每周提交一次)。